Back to Architecture Patterns
ApplicationEnterprise
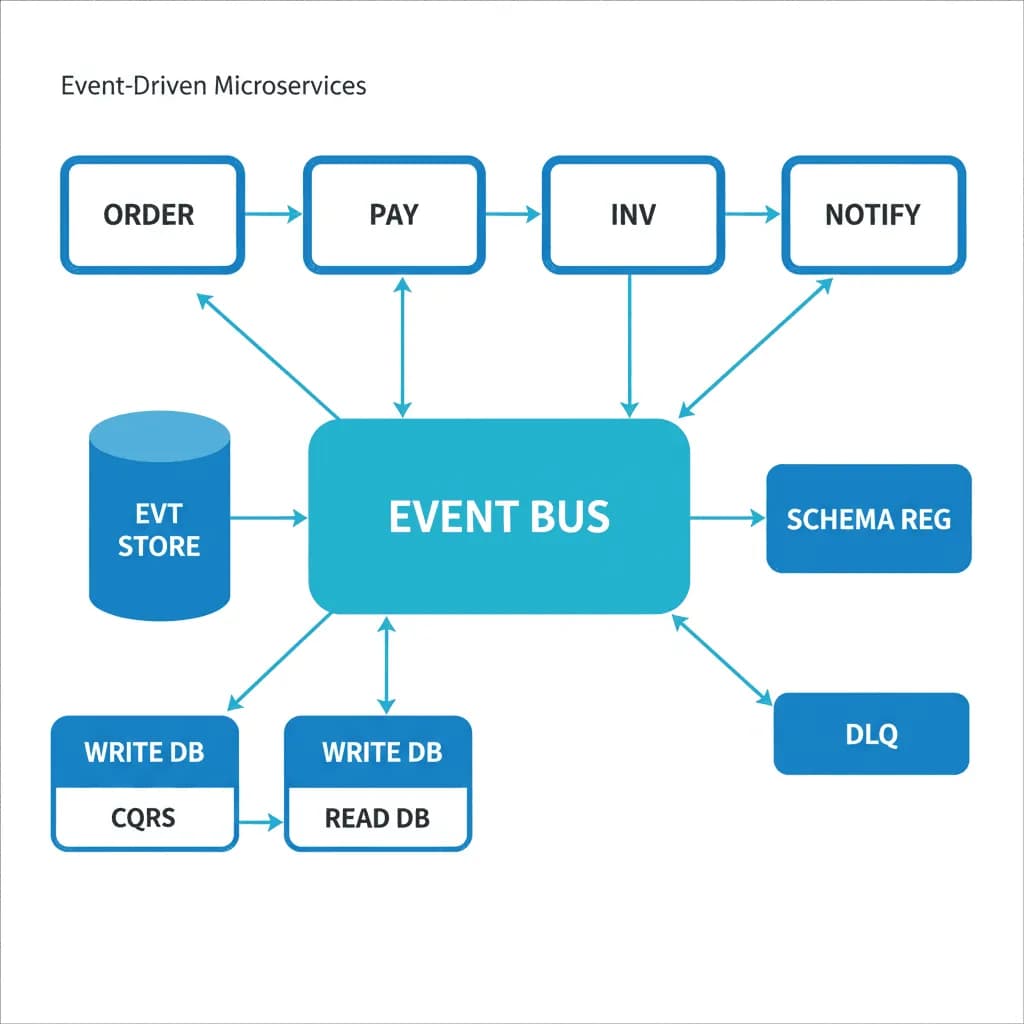
Event-Driven Microservices
Decouple everything. Let services communicate through events, not expectations about each other's uptime.
|
Discuss This Architecture3 topics covered
Application
Category
Enterprise
Complexity
Financial Services, E-Commerce
Industries
3+
Technologies

When You Need This
Your monolith is becoming a deployment bottleneck — every change requires coordinating across teams, and a bug in billing takes down the entire application. Or you're building a new system where different capabilities evolve at different rates: order management changes weekly, but inventory logic changes quarterly. You need services that can be developed, deployed, and scaled independently, communicating through events rather than synchronous API calls that create cascading failure chains.

Related Architecture Patterns
Explore more design patterns and system architectures


Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch