Back to Architecture Patterns
DataEnterprise
Data-Intensive Platform Architecture
When your competitive advantage is in your data, the platform that collects, transforms, stores, and surfaces that data is the most important thing you'll build.
|
Discuss This Architecture3 topics covered
Data
Category
Enterprise
Complexity
Healthcare, Financial Services
Industries
3+
Technologies

When You Need This
Your organization has data scattered across dozens of systems — CRM, ERP, billing, support tickets, sensor data, third-party APIs — and nobody can answer basic business questions without a week of manual data pulling. Reports are built in spreadsheets, analysts wait days for data engineering to prepare datasets, and the "single source of truth" is whichever database someone queried last. You need a data platform that ingests from all sources, transforms data into analysis-ready models, and serves insights to both dashboards and AI/ML systems. This isn't a data warehouse project — it's a platform that makes data a usable organizational asset.

Pattern Overview
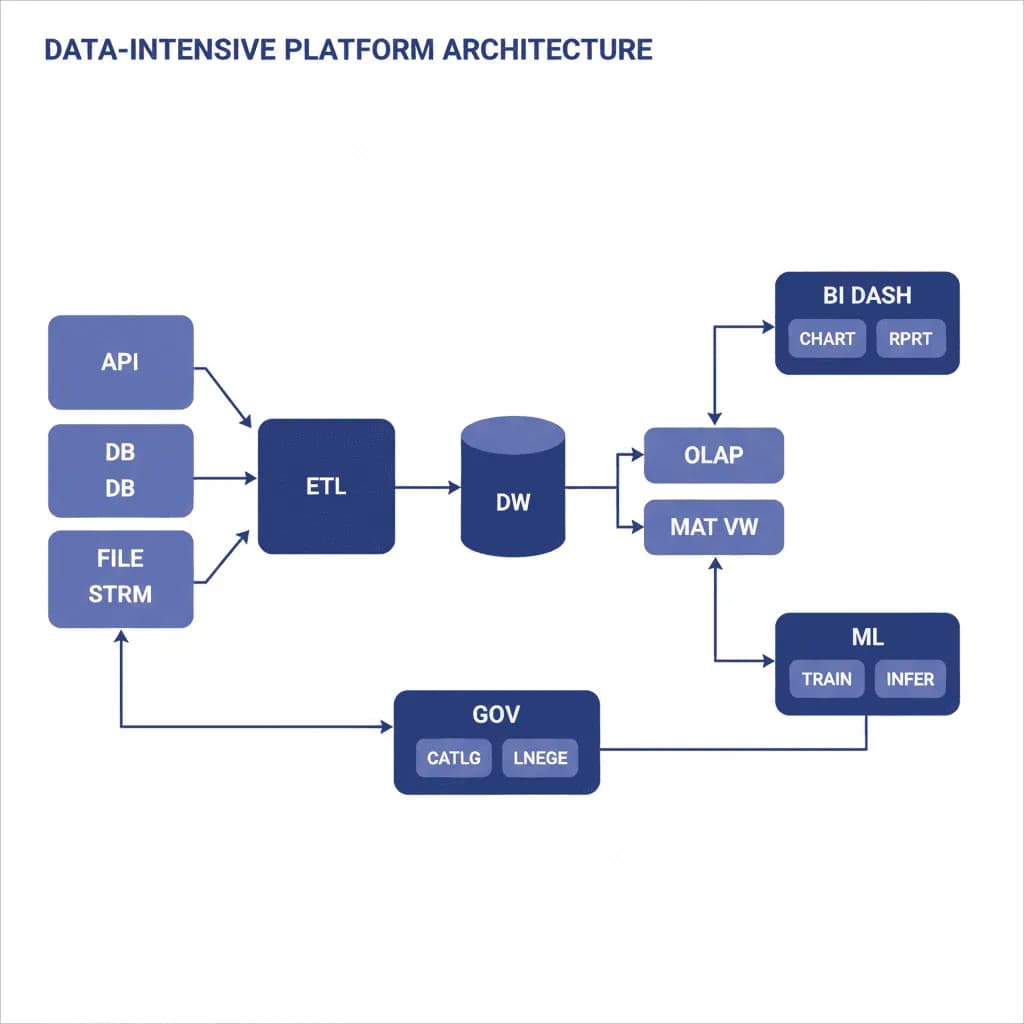
Data-intensive platform architecture creates a unified data infrastructure spanning ingestion, storage, transformation, and consumption. The ingestion layer pulls data from operational databases (CDC), APIs, event streams, and file uploads into a centralized data lake (raw, unprocessed). The transformation layer (dbt, Spark, or custom) cleans, models, and aggregates data into a data warehouse (structured, query-optimized). The consumption layer serves data to BI dashboards, API endpoints, ML feature stores, and embedded analytics. Data governance, lineage tracking, and access control operate across all layers.

Reference Architecture
Data flows through a medallion architecture: Bronze (raw ingestion), Silver (cleaned and conformed), Gold (business-ready aggregates). The Bronze layer stores raw data in Parquet format on S3/GCS, partitioned by source and ingestion timestamp — nothing is dropped, nothing is transformed. The Silver layer applies schema enforcement, deduplication, type casting, and joins across sources — this is where data becomes consistent. The Gold layer contains business-specific aggregates, denormalized tables, and pre-computed metrics optimized for specific use cases (dashboards, ML training, API serving).
Core Components
- Ingestion Layer: CDC connectors (Debezium, Fivetran, Airbyte) for database sources. API extractors for SaaS tools (Salesforce, HubSpot, Stripe). Event stream consumers for real-time data (Kafka). File processors for batch uploads (CSV, Excel, API dumps). All ingestion is incremental where possible, full-refresh only when necessary
- Storage Layer: Object storage (S3/GCS) with Parquet/Delta Lake format for the data lake. Cloud data warehouse (Snowflake, BigQuery, Redshift) for structured querying. The data lake holds everything (cheap, durable); the warehouse holds curated data (fast, expensive). Iceberg or Delta Lake table format for ACID transactions on the lake
- Transformation Layer: dbt (data build tool) for SQL-based transformations — models are version-controlled, tested, and documented. Spark or Databricks for large-scale transformations that exceed SQL capabilities. Orchestrated by Airflow, Dagster, or Prefect with dependency-aware scheduling, automatic retries, and SLA monitoring
- Data Governance: Column-level lineage tracking (what source field became what warehouse column). Access control with row-level security and column masking for PII. Data quality checks (Great Expectations, dbt tests) that block bad data from reaching the Gold layer. A data catalog (DataHub, Atlan) for discoverability

Design Decisions & Trade-offs
Data Lake vs. Data Warehouse vs. Lakehouse
Pure data lake (S3 + Parquet) is cheap and flexible but slow for interactive queries. Pure data warehouse (Snowflake, BigQuery) is fast for queries but expensive for storing everything. Lakehouse (Delta Lake, Iceberg on S3 + query engine) gives you both — lake economics with warehouse query performance. MW recommends the lakehouse pattern for new platforms: store everything in Delta Lake/Iceberg on S3, query through Snowflake/Databricks, and only duplicate to a traditional warehouse when query performance demands it.
dbt vs. Spark vs. Custom ETL
dbt for SQL-based transformations (which covers 80% of data engineering). Spark for heavy-lift transformations: large-scale joins, ML feature computation, unstructured data processing. Custom ETL (Python scripts) for edge cases that neither handles well (API calls within transformations, complex business logic). MW starts every engagement with dbt and only introduces Spark when a transformation demonstrably can't be expressed in SQL or exceeds SQL engine capabilities.
Batch vs. Streaming Ingestion
Batch (hourly/daily full or incremental loads) is simpler, cheaper, and sufficient for analytics that tolerate hourly freshness. Streaming (CDC via Debezium, real-time event consumers) is required when dashboards need minute-level freshness or downstream systems need near-real-time data sync. MW defaults to batch ingestion with CDC for the sources that need real-time, rather than streaming everything — the operational complexity of streaming pipelines isn't justified for sources where hourly freshness is fine.
Snowflake vs. BigQuery vs. Redshift
Snowflake for multi-cloud, separation of storage and compute, and the best cost model for variable workloads (auto-suspend, per-query scaling). BigQuery for GCP-native teams and workloads that benefit from serverless pricing (pay per query, not per cluster). Redshift for AWS-heavy organizations with steady, predictable query loads. MW has delivered on all three — the choice depends on existing cloud footprint, query patterns, and the team's SQL dialect preferences.
System Architecture Overview
Technology Choices
| Layer | Technologies |
|---|---|
| Ingestion | Fivetran, Airbyte, Debezium, custom Python extractors, Kafka Connect |
| Storage | S3/GCS (Parquet, Delta Lake, Iceberg), Snowflake, BigQuery, Redshift |
| Transformation | dbt, Apache Spark, Databricks, pandas (small-scale) |
| Orchestration | Airflow, Dagster, Prefect, dbt Cloud |
| Governance | DataHub, Atlan, Great Expectations, dbt tests, Monte Carlo (observability) |
| Consumption | Metabase, Looker, Superset, embedded analytics APIs, ML feature stores |
When to Use / When to Avoid
| Use When | Avoid When |
|---|---|
| Data is scattered across 5+ systems and no one has a unified view | You have one database and one dashboard — a direct connection is sufficient |
| Multiple teams (analysts, data scientists, product) need access to the same data | The data volume is small (< 1GB) and doesn't justify platform overhead |
| Compliance requires data lineage, access control, and audit trails on data access | You're building a transactional application, not an analytics platform |
| ML/AI features need curated, feature-store-ready datasets | The organization doesn't have data engineering capacity to operate the platform |
Our Approach
MW builds data platforms with a "quick-wins-first" approach — we identify the 3-5 most painful data questions the organization can't currently answer, build the minimum pipeline to answer them, and expand from there. We don't start with a 6-month "build the data lake" project. Our dbt projects include comprehensive testing (uniqueness, not-null, referential integrity, custom business rules), documentation (every model and column described), and freshness monitoring. We've built data platforms processing 50M+ rows/day for healthcare auditing, inventory management, and financial reporting — and the consistent lesson is that data quality controls are the hardest and most important part.

Related Blueprints
- Intelligent Inventory Management System — Real-time inventory analytics from multi-source data
- Custom ERP for Manufacturing — Manufacturing data integration across production systems
- Supply Chain Visibility Platform — Cross-partner data aggregation and analytics

Related Case Studies
- Healthcare Auditing — Healthcare data auditing platform with compliance-grade lineage and access controls
- AI Accounting — Invoice OCR — Document extraction feeding into financial data pipelines
- Vendor Discovery — B2B supplier data aggregation with Elasticsearch-powered search
Related Technologies
Cloud SolutionsAI DevelopmentDigital Consulting
Related Architecture Patterns
Explore more design patterns and system architectures

Data
Real-Time Streaming Systems
Batch is a special case of streaming. When your business needs to react in seconds instead of hours, you need an architecture built for continuous data flow.
EnterpriseView

Infrastructure
Security-First Architecture
Security isn't a feature you add after launch. It's an architectural property — either the system was designed for it, or it wasn't.
EnterpriseView

Infrastructure
Serverless-First Architecture
Pay for what you use, scale to zero when you don't, and stop managing servers entirely — but know when the economics stop working.
AdvancedView
Frequently Asked Questions
MicrocosmWorks implements tiered storage architectures where hot data lives in fast query engines like ClickHouse or Apache Druid, warm data moves to columnar formats in object storage queried via Trino or Athena, and cold data archives to cost-optimized storage classes with lifecycle policies. We use streaming ingestion with backpressure controls that prevent upstream systems from overwhelming the platform, combined with intelligent partitioning and compaction strategies that keep query performance consistent as data volume grows. This tiered approach typically reduces storage costs by 70-85% compared to keeping all data in a single high-performance tier.
MicrocosmWorks builds lambda or kappa architectures depending on your consistency requirements—lambda uses separate batch and streaming pipelines that merge at the serving layer, while kappa processes everything as a stream and materializes views for different query patterns. For most clients, we recommend a unified streaming approach with Apache Flink or Spark Structured Streaming that writes to both a real-time serving store (Redis, Druid) and a batch-optimized lakehouse (Delta Lake, Apache Iceberg). This eliminates the dual-pipeline maintenance burden of traditional lambda architectures while supporting both sub-second dashboard queries and multi-hour analytical workloads.
MicrocosmWorks implements data quality as a first-class pipeline stage using tools like Great Expectations or dbt tests that validate schema conformance, null rates, value distributions, referential integrity, and freshness at every transformation boundary. We build data quality dashboards that surface issues immediately and automated circuit breakers that halt downstream processing when upstream data quality drops below acceptable thresholds, preventing bad data from propagating through the platform. Every data contract between producers and consumers is codified in version-controlled schemas with SLOs for completeness, accuracy, and timeliness.
MicrocosmWorks recommends a platform team of 3-5 engineers who own the shared infrastructure—ingestion pipelines, compute clusters, storage layers, and query engines—while domain teams own their specific data models, transformations, and quality rules as self-service consumers of the platform. We help clients establish a data engineering guild model with shared standards for naming conventions, testing practices, and deployment patterns that prevent the platform from becoming a patchwork of inconsistent implementations. For organizations not ready to build a full platform team, MicrocosmWorks provides managed platform engineering at $15-$45/hr with knowledge transfer built into the engagement.
MicrocosmWorks runs dual-write migrations where new data flows to both the legacy warehouse and the modern platform simultaneously, with automated reconciliation jobs that compare query results between both systems to verify correctness before cutting over consumers. We migrate reports and dashboards in priority order, starting with the most-accessed assets and working through the long tail, with each migration validated by the business owners who use those reports daily. This approach typically takes 3-6 months for mid-size data platforms and ensures zero disruption to business decision-making throughout the migration.
Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch