Zurück zu Architekturmustern
AI / DataEnterprise
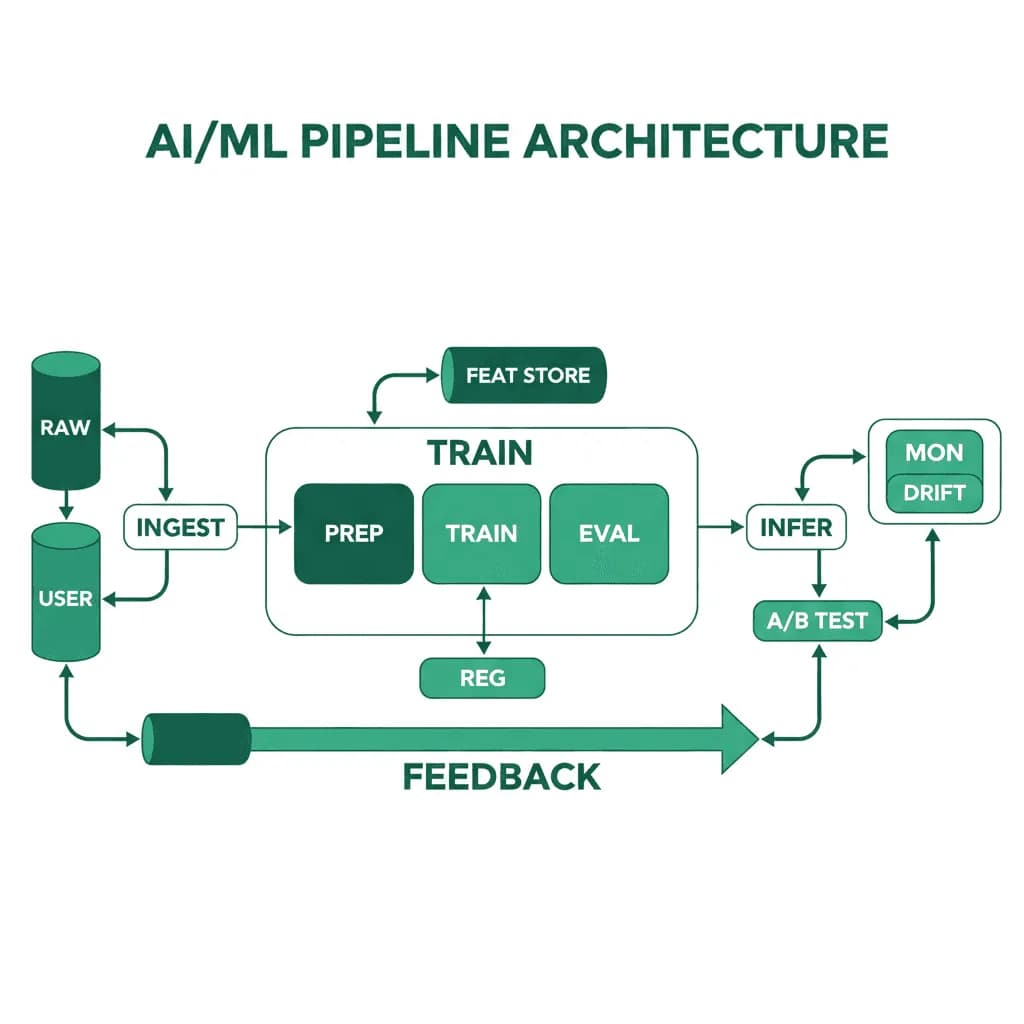
AI/ML Pipeline-Architektur
Modelle laufen nicht von allein. Die Pipeline, die Ihre Modelle trainiert, validiert, bereitstellt und überwacht, ist das eigentliche Produkt – das Modell ist nur ein Artefakt.
|
Diskutieren Sie diese Architektur3 topics covered
AI / Data
Category
Enterprise
Complexity
Gesundheitswesen, Finanzdienstleistungen
Industries
3+
Technologies

Wann Sie dies benötigen
Sie haben bewiesen, dass ein ML-Modell in einem Notebook funktioniert. Jetzt benötigen Sie es in der Produktion – um Vorhersagen in großem Maßstab zu liefern, mit neuen Daten neu zu trainieren, auf Drift zu überwachen und ein Rollback durchzuführen, wenn ein neues Modell schlechter abschneidet als das aktuelle. Die Lücke zwischen einem funktionierenden Prototyp und einem Produktions-ML-System ist enorm. Sie benötigen eine Pipeline, die Datenerfassung, Feature Engineering, Training, Validierung, Bereitstellung und Überwachung als wiederholbaren, automatisierten Prozess handhabt. Ohne dies ist Ihr „AI-Produkt“ ein Notebook, das ein Data Scientist jede Woche manuell erneut ausführt.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen