Zurück zu Architekturmustern
AI / DataEnterprise
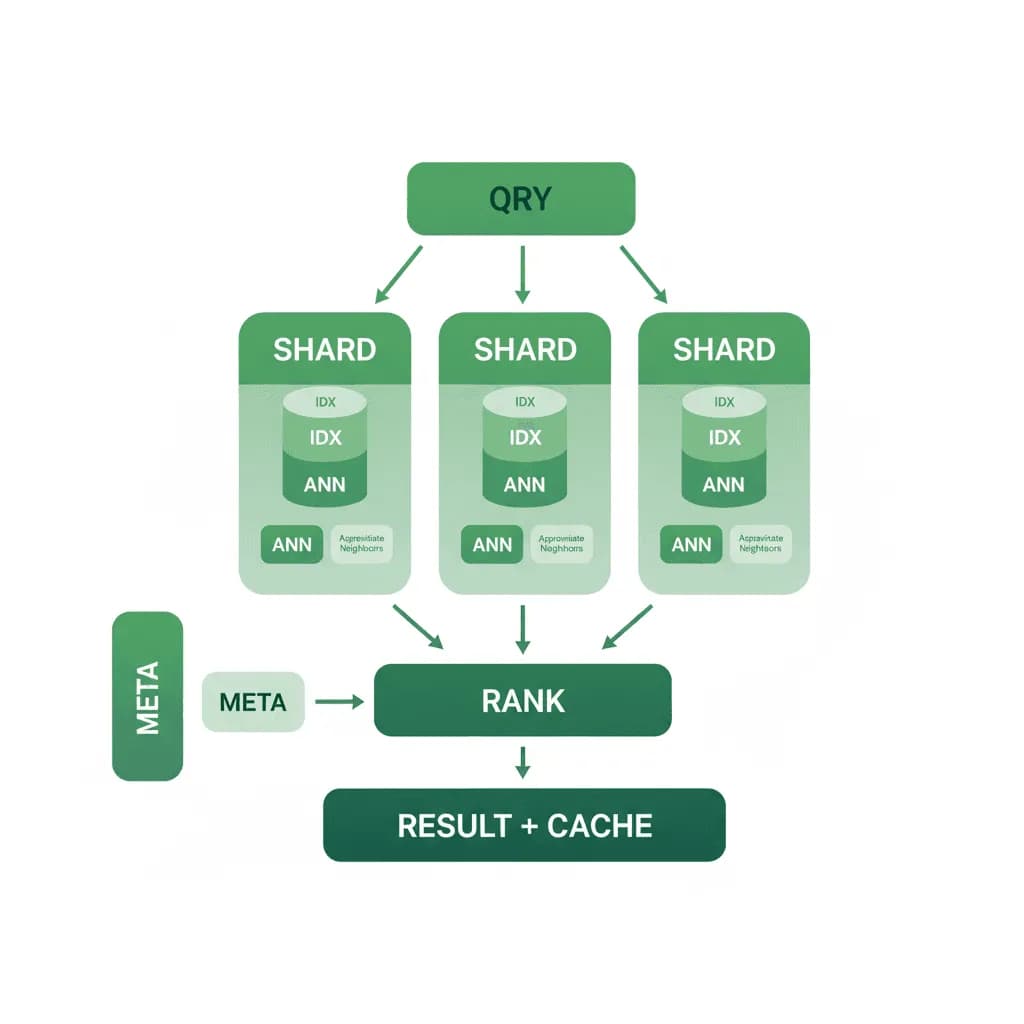
Skalierbare Vektordatenbank-Architektur
Die Embedding-Suche ist bei 10.000 Vektoren einfach. Bei 100 Millionen Vektoren mit einer P99-Latenz von unter 100 ms wird es zu einem Infrastrukturproblem – und genau das löst dieses Muster.
|
Diskutieren Sie diese Architektur2 topics covered
AI / Data
Category
Enterprise
Complexity
AI/ML, E-Commerce
Industries
2+
Technologies

Wann Sie dies benötigen
Ihre RAG-Pipeline oder Ihr Empfehlungssystem funktioniert in der Entwicklung mit ein paar tausend Vektoren wunderbar. Jetzt haben Sie 50 Millionen Embeddings, Abfragen benötigen eine Latenz von unter 100 ms, der Index wächst stetig, und Sie verbrauchen immer mehr Speicher. Sie benötigen eine Vektordatenbank-Architektur, die horizontal skaliert, den Speicher effizient verwaltet (nicht alles muss im RAM liegen), gleichzeitige Schreibvorgänge während der Ingestion ohne Beeinträchtigung der Abfrageleistung verarbeitet und keine 10.000 $/Monat an Infrastrukturkosten verursacht für das, was im Grunde ein Suchindex ist.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen