Zurück zu Architekturmustern
DataEnterprise
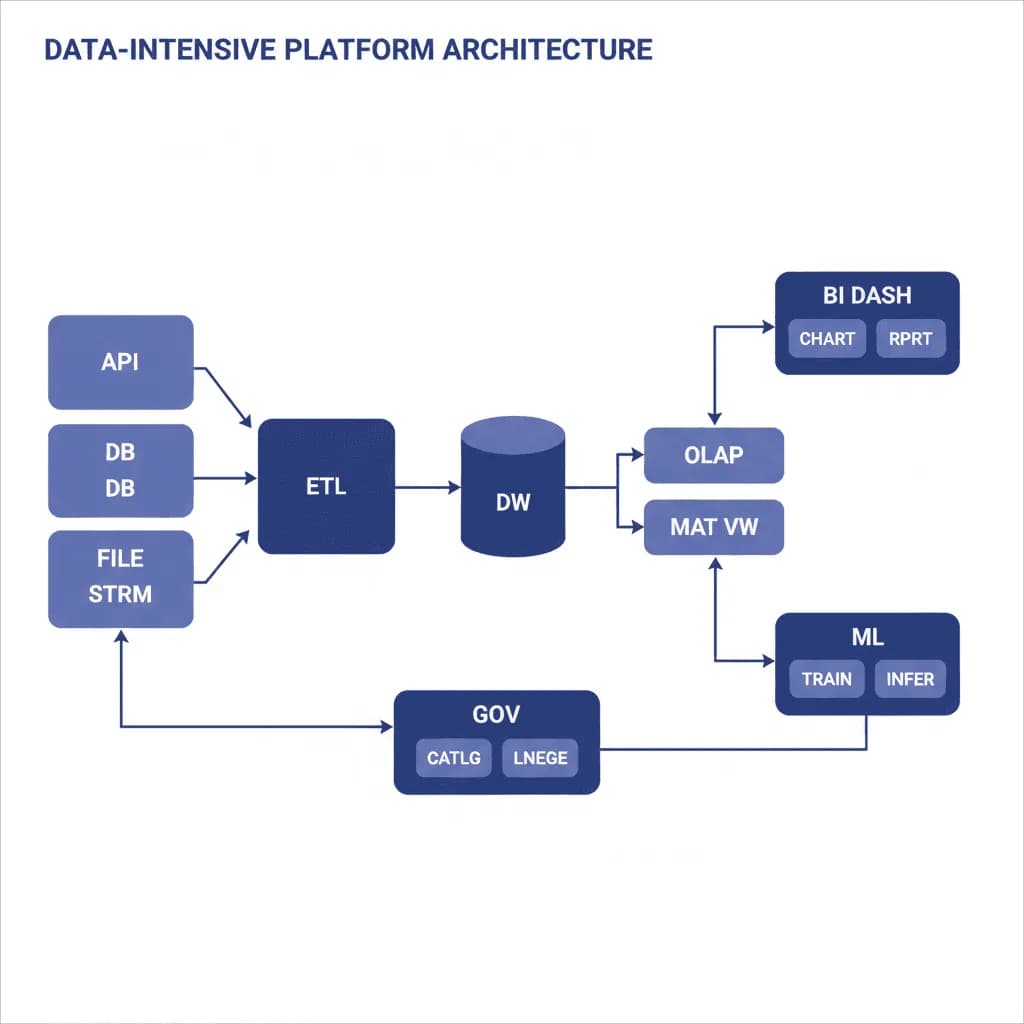
Datenintensive Plattformarchitektur
Wenn Ihr Wettbewerbsvorteil in Ihren Daten liegt, ist die Plattform, die diese Daten sammelt, transformiert, speichert und zugänglich macht, das Wichtigste, was Sie entwickeln werden.
|
Diskutieren Sie diese Architektur3 topics covered
Data
Category
Enterprise
Complexity
Gesundheitswesen, Finanzdienstleistungen
Industries
3+
Technologies

Wann Sie dies benötigen
Ihre Organisation verfügt über Daten, die über Dutzende von Systemen verstreut sind – CRM, ERP, Abrechnung, Support-Tickets, Sensordaten, Drittanbieter-APIs – und niemand kann grundlegende Geschäftsfragen ohne eine Woche manueller Datenbeschaffung beantworten. Berichte werden in Tabellenkalkulationen erstellt, Analysten warten tagelang darauf, dass Data Engineering Datensätze vorbereitet, und die „einzige Quelle der Wahrheit“ ist die Datenbank, die zuletzt abgefragt wurde. Sie benötigen eine Datenplattform, die Daten aus allen Quellen aufnimmt, in analysebereite Modelle umwandelt und Erkenntnisse sowohl für Dashboards als auch für AI/ML-Systeme bereitstellt. Dies ist kein Data Warehouse-Projekt – es ist eine Plattform, die Daten zu einem nutzbaren organisatorischen Vermögenswert macht.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen