Zurück zu Architekturmustern
InfrastructureAdvanced
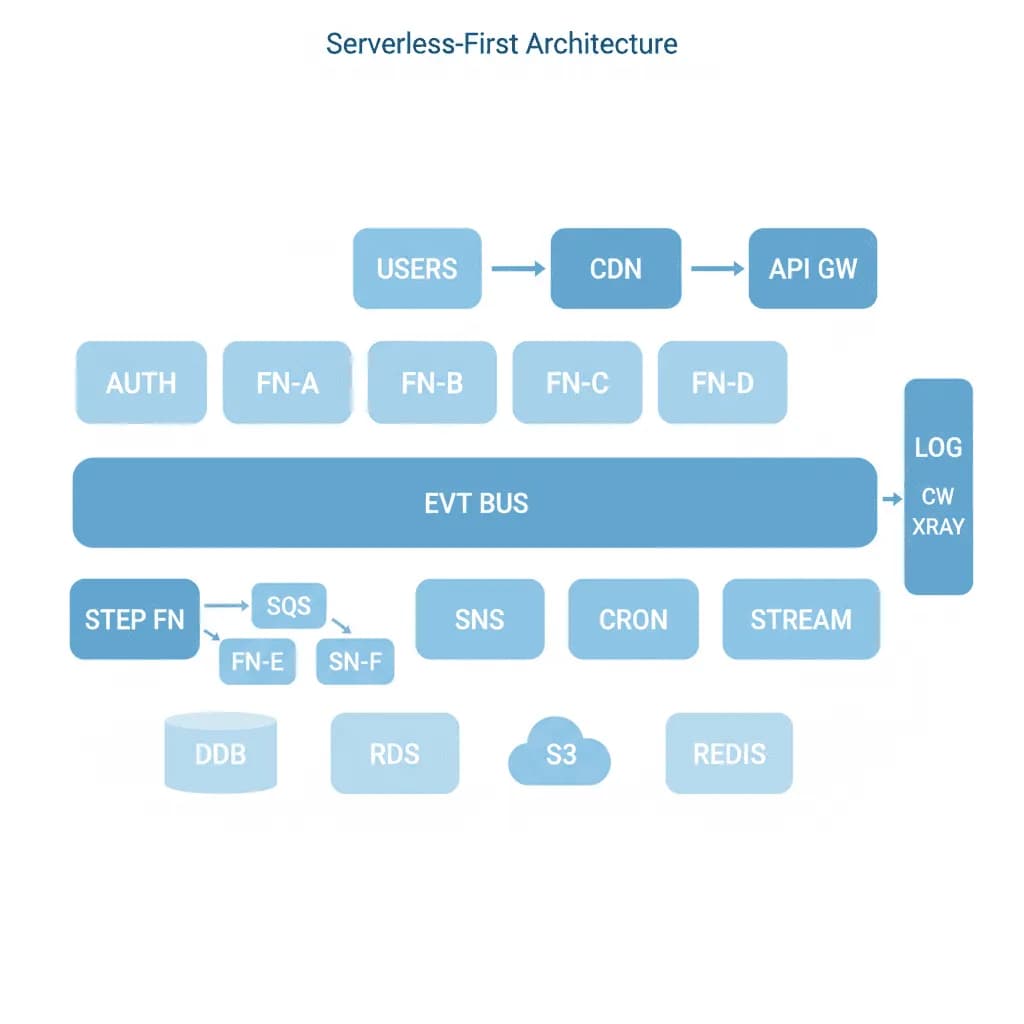
Serverless-First-Architektur
Bezahlen Sie nur für das, was Sie nutzen, skalieren Sie auf Null, wenn Sie es nicht nutzen, und hören Sie ganz auf, Server zu verwalten – aber wissen Sie, wann sich die Wirtschaftlichkeit nicht mehr lohnt.
|
Diskutieren Sie diese Architektur2 topics covered
Infrastructure
Category
Advanced
Complexity
SaaS, Medien
Industries
2+
Technologies

Wann Sie dies benötigen
Ihre Anwendung hat variablen Datenverkehr – nachts ruhig, Spitzen während der Geschäftszeiten und unvorhersehbare Spitzen durch Marketingkampagnen oder saisonale Ereignisse. Sie bezahlen für Server, die 70 % der Zeit untätig sind. Oder Sie entwickeln ein neues Produkt und möchten nicht in die Bereitstellung von Infrastruktur, Kapazitätsplanung und Bereitschaftsdienste investieren, bevor Sie die Produkt-Markt-Passung validiert haben. Serverless bietet Ihnen eine Preisgestaltung pro Anfrage, automatische Skalierung und null Infrastrukturverwaltung – aber nur, wenn die Workload-Eigenschaften passen.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen