Zurück zu Architekturmustern
InfrastructureEnterprise
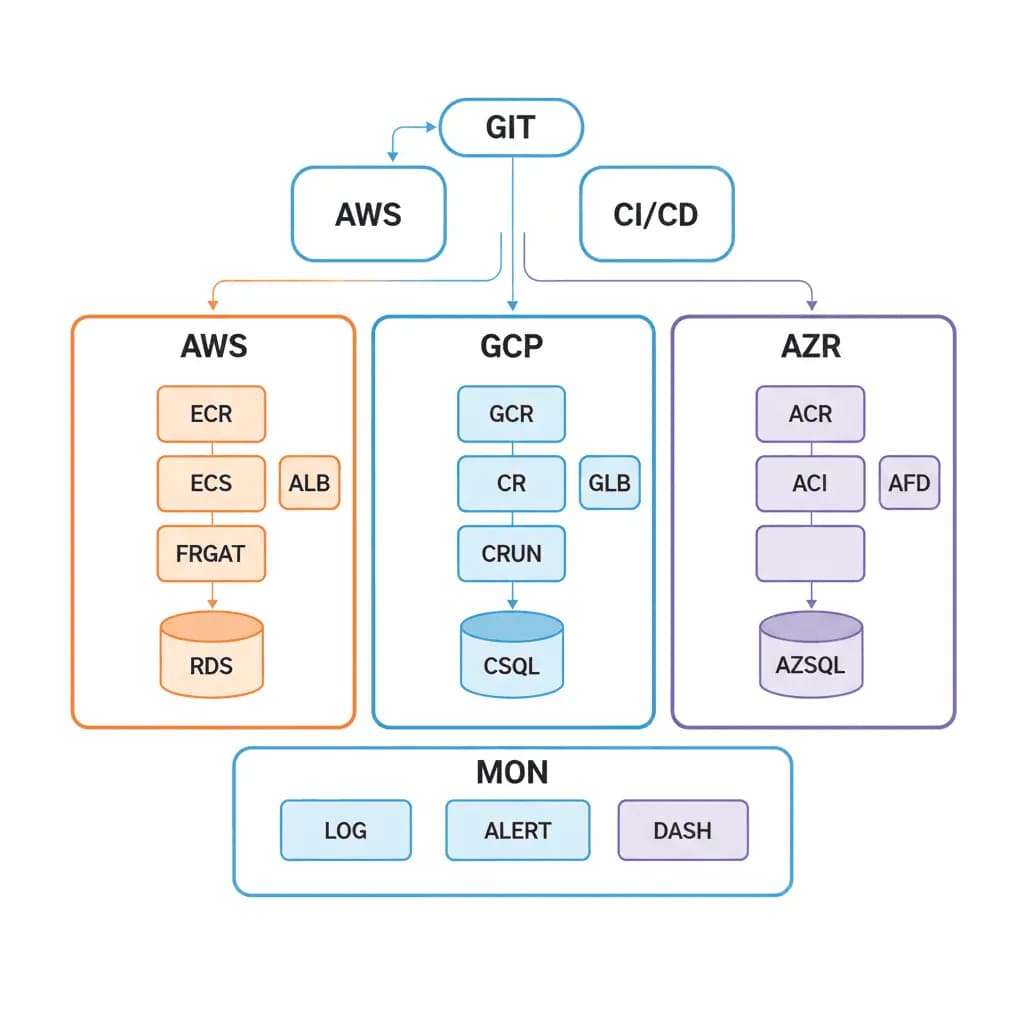
Cloud-native Infrastruktur
Infrastruktur, die wie Anwendungscode versioniert, getestet und bereitgestellt wird – denn Ihre Plattform ist nur so zuverlässig wie das, was ihr zugrunde liegt.
|
Diskutieren Sie diese Architektur2 topics covered
Infrastructure
Category
Enterprise
Complexity
Enterprise SaaS, Financial Services
Industries
2+
Technologies

Wann Sie dies benötigen
Ihre Infrastruktur wird durch Klicken in Cloud-Konsolen verwaltet. Umgebungsdrift zwischen Staging und Produktion führt zu „läuft auf meinem Rechner“-Problemen auf Infrastrukturebene. Skalierung erfordert manuelle Eingriffe, Bereitstellungen beinhalten SSH-Verbindungen zu Servern, und die Notfallwiederherstellung ist ein Google Doc, das niemand getestet hat. Sie benötigen Infrastruktur, die reproduzierbar, versionskontrolliert, selbstheilend und beobachtbar ist – Infrastruktur, die ein Team ohne Expertenwissen betreiben kann.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen