Back to Architecture Patterns
InfrastructureEnterprise
Edge Computing & IoT Architecture
Process data where it's generated. Not everything needs to round-trip to the cloud — and for many IoT workloads, it can't.
|
Discuss This Architecture3 topics covered
Infrastructure
Category
Enterprise
Complexity
Manufacturing, Agriculture
Industries
3+
Technologies

When You Need This
You have devices in the field — sensors on factory floors, cameras in warehouses, monitors on agricultural equipment, wearables on patients — generating data that needs to be processed, acted on, and selectively transmitted to the cloud. Latency to a cloud region is too high for real-time decisions. Bandwidth is too expensive or unreliable to stream everything. Devices need to function when the network is down. You need an architecture that distributes intelligence across the edge, fog, and cloud layers based on where each decision needs to be made.

Pattern Overview
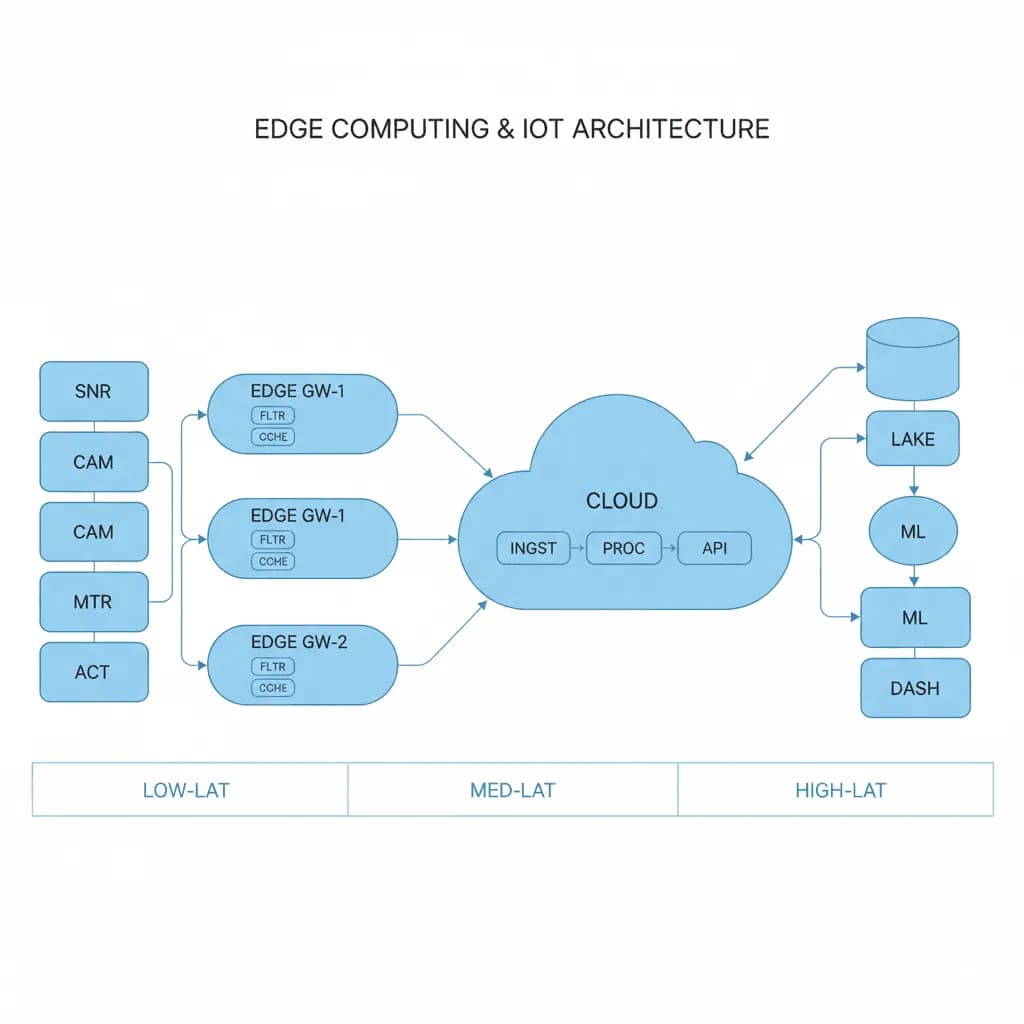
Edge-fog-cloud architecture distributes computation across three tiers. Edge devices collect sensor data and run lightweight inference (anomaly detection, threshold alerts). Fog nodes (on-premise gateways or local servers) aggregate data from multiple edge devices, run more complex models, and manage device fleets. Cloud services handle long-term storage, model training, fleet-wide analytics, and management dashboards. The architecture accounts for intermittent connectivity, device heterogeneity, over-the-air updates, and security at every tier.

Reference Architecture
Data flows upward through the tiers with intelligence at each layer. Edge devices publish sensor readings to fog nodes via MQTT or CoAP. Fog nodes run stream processing (Apache NiFi, AWS Greengrass, or custom) to filter, aggregate, and enrich data before forwarding to cloud. Cloud ingestion (Kinesis, IoT Core, or Event Hubs) routes data to time-series databases, data lakes, and ML training pipelines. Commands and OTA updates flow downward through the same path. A device shadow/twin system maintains the last-known state of every device for query and reconciliation.
Core Components
- Device Layer: Microcontrollers or SBCs (ESP32, Raspberry Pi, Jetson Nano) running firmware with MQTT client, local data buffering, and edge inference (TensorFlow Lite, ONNX Runtime). Store-and-forward for offline operation
- Fog/Gateway Layer: On-premise gateways running containerized services. Protocol translation (Modbus/BACnet to MQTT), data aggregation, local rule engines, and fleet management. Runs on industrial PCs, AWS Outposts, or Azure Stack Edge
- Cloud Ingestion & Processing: AWS IoT Core / Azure IoT Hub for device management, message routing, and shadow/twin state. Kinesis/Event Hubs for stream processing. Time-series database (InfluxDB, TimescaleDB) for operational data
- Device Management: Over-the-air firmware updates, certificate rotation, fleet grouping, remote diagnostics, and device lifecycle management (provisioning, decommissioning)

Design Decisions & Trade-offs
MQTT vs. HTTP vs. CoAP
MQTT is the default for IoT — it's lightweight, supports QoS levels (at-most-once through exactly-once), and handles flaky connections gracefully with persistent sessions. HTTP is appropriate when devices have reliable connectivity and the interaction is request-response. CoAP for extremely constrained devices (< 256KB RAM) on lossy networks. MW defaults to MQTT with QoS 1 (at-least-once) for sensor data and QoS 2 (exactly-once) for commands.
Edge Inference vs. Cloud Inference
Run inference at the edge when latency matters (real-time alerts, safety systems), bandwidth is expensive (video streams), or privacy requires it (healthcare wearables). Run in the cloud when the model is too large for edge hardware, when training data from multiple sites improves accuracy, or when the inference result doesn't need to be real-time. MW designs for a hybrid model: lightweight anomaly detection at the edge, complex classification in the cloud.
Time-Series Database Selection
InfluxDB for operational monitoring with moderate cardinality. TimescaleDB when you need SQL compatibility and want to join time-series data with relational data. ClickHouse when query performance at scale is the priority. MW evaluates based on cardinality (number of unique time series), query patterns (point lookups vs. range scans vs. aggregations), and retention requirements.
Offline-First Design
Edge devices must function without cloud connectivity. MW implements local data buffering with bounded queues (configurable by time and size), conflict resolution for bidirectional sync (last-write-wins or domain-specific merge), and graceful degradation where devices continue operating with stale configuration until reconnection.
System Architecture Overview
Technology Choices
| Layer | Technologies |
|---|---|
| Edge Devices | ESP32, Raspberry Pi, Jetson Nano/Orin, STM32, custom PCBs |
| Protocols | MQTT (Mosquitto, EMQX), CoAP, Modbus, BACnet, LoRaWAN, BLE |
| Fog/Gateway | AWS Greengrass, Azure IoT Edge, Apache NiFi, Docker on industrial PCs |
| Cloud IoT | AWS IoT Core, Azure IoT Hub, GCP IoT, custom MQTT brokers |
| Data | InfluxDB, TimescaleDB, ClickHouse, S3/Parquet for cold storage |
| ML at Edge | TensorFlow Lite, ONNX Runtime, NVIDIA TensorRT (Jetson) |
When to Use / When to Avoid
| Use When | Avoid When |
|---|---|
| Devices generate high-volume data that's expensive to transmit entirely | All devices have reliable, low-latency cloud connectivity |
| Real-time decisions need < 100ms response (safety, control systems) | The workload is purely data collection with batch cloud processing |
| Devices must function during network outages | You have < 50 devices and can manage them individually |
| Privacy/compliance requires processing data locally before cloud transmission | The "edge" is actually a web browser — that's a different architecture |
Our Approach
MW designs IoT architectures with a "data gravity" lens — we map where each data type needs to be processed (edge, fog, or cloud) based on latency requirements, bandwidth costs, and decision granularity. We don't push everything to the cloud and filter later. Our edge deployments include automated device provisioning with certificate-based authentication, OTA update pipelines with staged rollouts and automatic rollback, and local dashboards on fog nodes for on-site operators who can't wait for cloud round-trips.

Related Blueprints
- Predictive Maintenance for Smart Factories — Edge inference for vibration analysis and failure prediction
- Smart Consumer Product IoT Platform — Consumer device management with cloud analytics
- Connected Fleet Management System — Vehicle telemetry with edge processing and cloud aggregation
- Smart Building Energy Management — BACnet/Modbus integration with fog-layer optimization
- Agricultural IoT Monitoring & Analytics — LoRaWAN sensor networks with offline-first design
- Wearable Health Device Platform — BLE wearables with on-device health inference

Related Case Studies
- AI Surveillance System — Edge inference with RTSP camera streams and fog-layer aggregation
- Video Analysis — Real-time video processing with edge-cloud hybrid inference
Related Technologies
IoT DevelopmentCloud SolutionsAI Development
Related Architecture Patterns
Explore more design patterns and system architectures

Infrastructure
Security-First Architecture
Security isn't a feature you add after launch. It's an architectural property — either the system was designed for it, or it wasn't.
EnterpriseView

Infrastructure
Serverless-First Architecture
Pay for what you use, scale to zero when you don't, and stop managing servers entirely — but know when the economics stop working.
AdvancedView

Infrastructure
On-Off Scaling Architecture
Don't pay for idle GPUs. Provision compute just-in-time, process the workload, and tear it down — turning capital expense into a per-job operating cost.
AdvancedView
Frequently Asked Questions
MicrocosmWorks uses a decision framework based on latency sensitivity, bandwidth cost, and data privacy requirements to partition workloads between edge and cloud. Time-critical tasks like anomaly detection on sensor data, local control loops, and safety shutoffs run at the edge, while model training, historical analytics, and cross-site aggregation stay in the cloud. We help clients map each IoT use case to the right compute tier during our architecture discovery phase.
MicrocosmWorks designs edge nodes with local persistence using lightweight databases like SQLite or TimescaleDB, combined with store-and-forward queuing that buffers data during connectivity gaps and synchronizes automatically when the connection is restored. Our edge firmware includes conflict resolution logic for scenarios where local decisions made offline diverge from cloud-side state. This ensures zero data loss and continuous operation even in environments with intermittent connectivity like remote industrial sites or mobile fleets.
MicrocosmWorks implements OTA (over-the-air) update pipelines with cryptographic signing, staged rollouts, and automatic rollback capabilities to ensure every edge device receives verified firmware without downtime risk. We use mutual TLS authentication between edge devices and the update server, with hardware-backed secure boot to prevent tampered firmware from executing. Our phased deployment strategy updates devices in small batches with health checks between stages, so a bad update never reaches your full fleet.
MicrocosmWorks selects edge hardware based on the workload profile—NVIDIA Jetson for computer vision and ML inference, AWS IoT Greengrass-compatible gateways for general-purpose edge computing, and ruggedized industrial PCs from vendors like Advantech for harsh manufacturing environments. We maintain reference architectures for each platform that include pre-configured networking, security, and telemetry stacks, which accelerates deployment by 40-60%. Our team evaluates power consumption, operating temperature range, and connectivity options to match your specific site conditions.
MicrocosmWorks has completed multiple SCADA modernization projects where we overlay edge computing gateways that translate legacy protocols like Modbus and OPC-UA into modern MQTT or gRPC streams without disrupting existing control systems. We run a parallel architecture during migration so the legacy SCADA continues operating while the new edge-cloud pipeline is validated against production data. Our consulting rates for industrial IoT modernization start at $20-$50/hr depending on the protocol complexity and regulatory requirements involved.
Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch