Back to Architecture Patterns
InfrastructureAdvanced
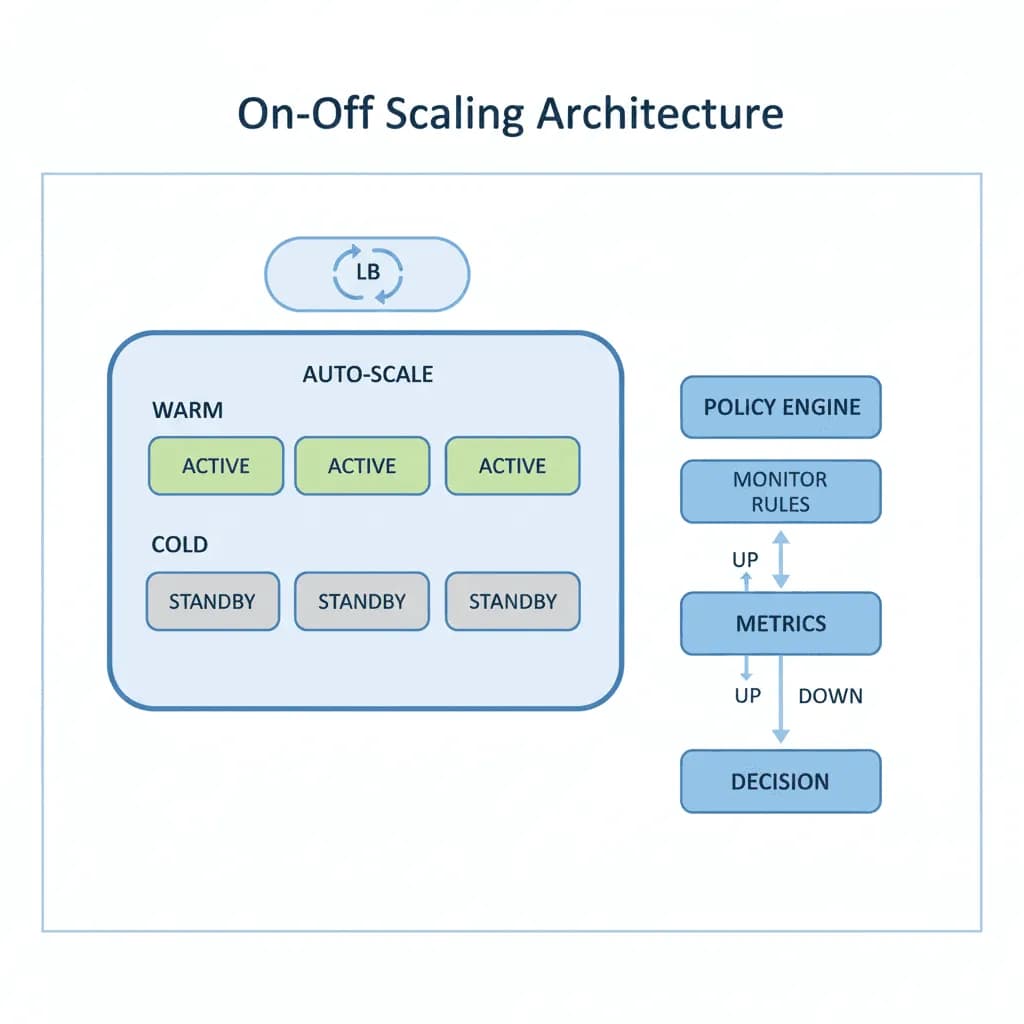
On-Off Scaling Architecture
Don't pay for idle GPUs. Provision compute just-in-time, process the workload, and tear it down — turning capital expense into a per-job operating cost.
|
Discuss This Architecture2 topics covered
Infrastructure
Category
Advanced
Complexity
AI/ML, Media & Entertainment
Industries
2+
Technologies

When You Need This
Your workload is bursty — video encoding jobs that spike when content is uploaded, ML training runs that need 8 GPUs for 4 hours then nothing, batch inference jobs triggered by business events, or rendering pipelines that run overnight. You're either over-provisioned (paying for idle resources 80% of the time) or under-provisioned (jobs queue for hours during peaks). You need an architecture that provisions exactly the compute you need, when you need it, and releases it when the job completes — without the cold-start penalty that makes "scale to zero" impractical for GPU workloads.

Related Architecture Patterns
Explore more design patterns and system architectures


Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch