Zurück zu Architekturmustern
InfrastructureAdvanced
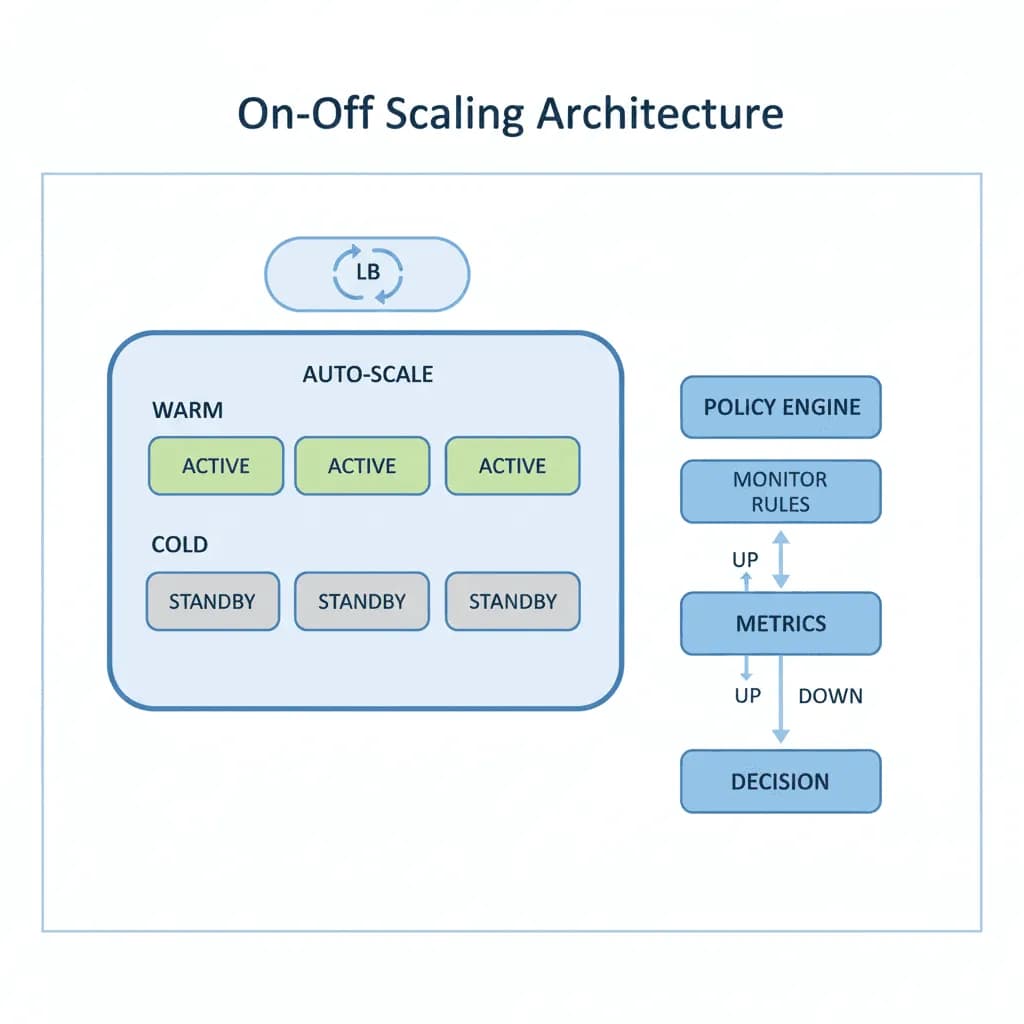
On-Off-Skalierungsarchitektur
Bezahlen Sie nicht für inaktive GPUs. Stellen Sie Rechenleistung just-in-time bereit, verarbeiten Sie die Workload und fahren Sie sie wieder herunter – wodurch Investitionsausgaben zu laufenden Kosten pro Auftrag werden.
|
Diskutieren Sie diese Architektur2 topics covered
Infrastructure
Category
Advanced
Complexity
AI/ML, Media & Entertainment
Industries
2+
Technologies

Wann Sie das brauchen
Ihre Workload ist sprunghaft – Video-Encoding-Aufträge, die bei Uploads ansteigen, ML-Trainingsläufe, die 8 GPUs für 4 Stunden benötigen und dann nichts, Batch Inference-Jobs, die durch Geschäftsereignisse ausgelöst werden, oder Rendering-Pipelines, die über Nacht laufen. Sie sind entweder überversorgt (zahlen 80 % der Zeit für inaktive Ressourcen) oder unterversorgt (Jobs stehen während Spitzenzeiten stundenlang in der Warteschlange). Sie benötigen eine Architektur, die genau die Rechenleistung bereitstellt, die Sie benötigen, wenn Sie sie benötigen, und diese freigibt, wenn der Auftrag abgeschlossen ist – ohne die Kaltstartstrafe, die „scale to zero“ für GPU-Workloads unpraktisch macht.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen