Back to Architecture Patterns
InfrastructureEnterprise
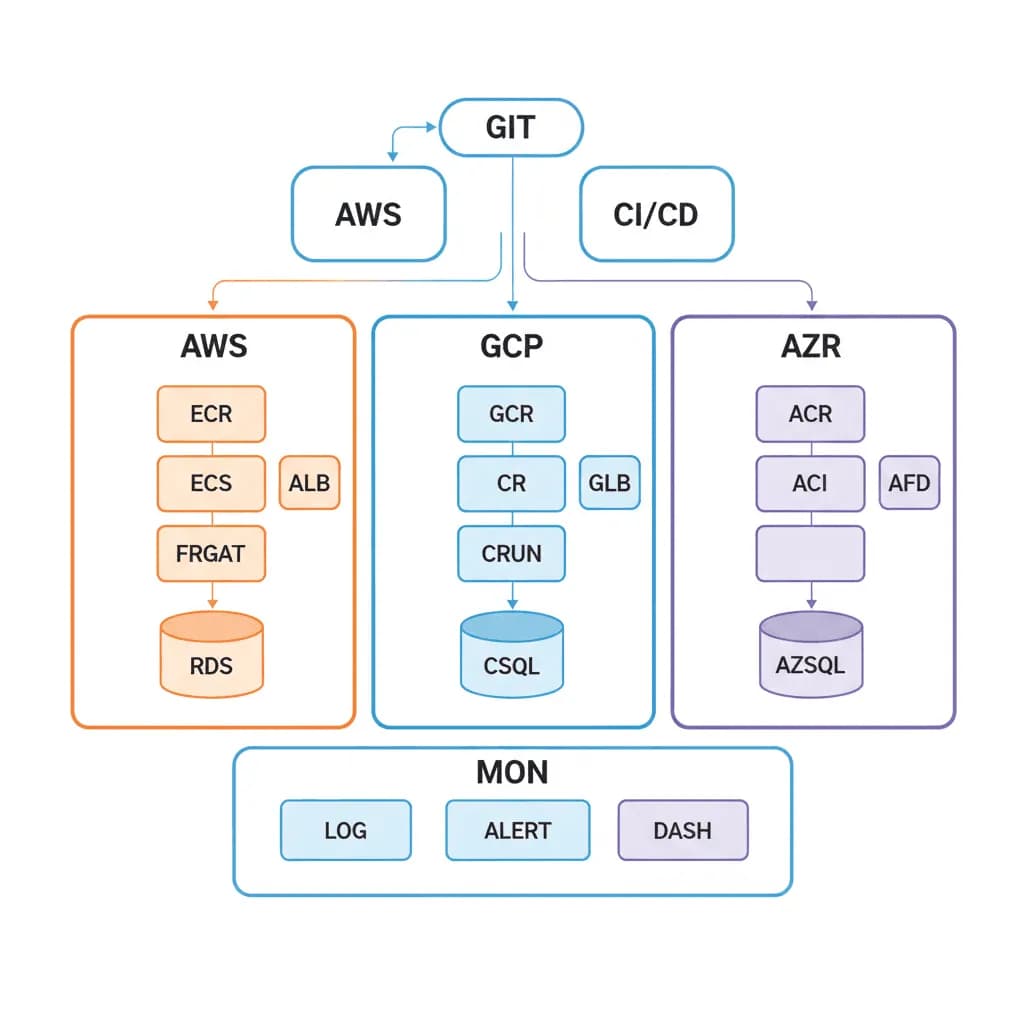
Cloud-Native Infrastructure
Infrastructure that's versioned, tested, and deployed like application code — because your platform is only as reliable as what's underneath it.
|
Discuss This Architecture2 topics covered
Infrastructure
Category
Enterprise
Complexity
Enterprise SaaS, Financial Services
Industries
2+
Technologies

When You Need This
Your infrastructure is managed by clicking through cloud consoles. Environment drift between staging and production causes "works on my machine" issues at the infrastructure level. Scaling requires manual intervention, deployments involve SSH-ing into servers, and disaster recovery is a Google Doc that nobody has tested. You need infrastructure that's reproducible, version-controlled, self-healing, and observable — infrastructure that a team can operate without hero knowledge.

Related Architecture Patterns
Explore more design patterns and system architectures


Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch