Zurück zu Architekturmustern
DataEnterprise
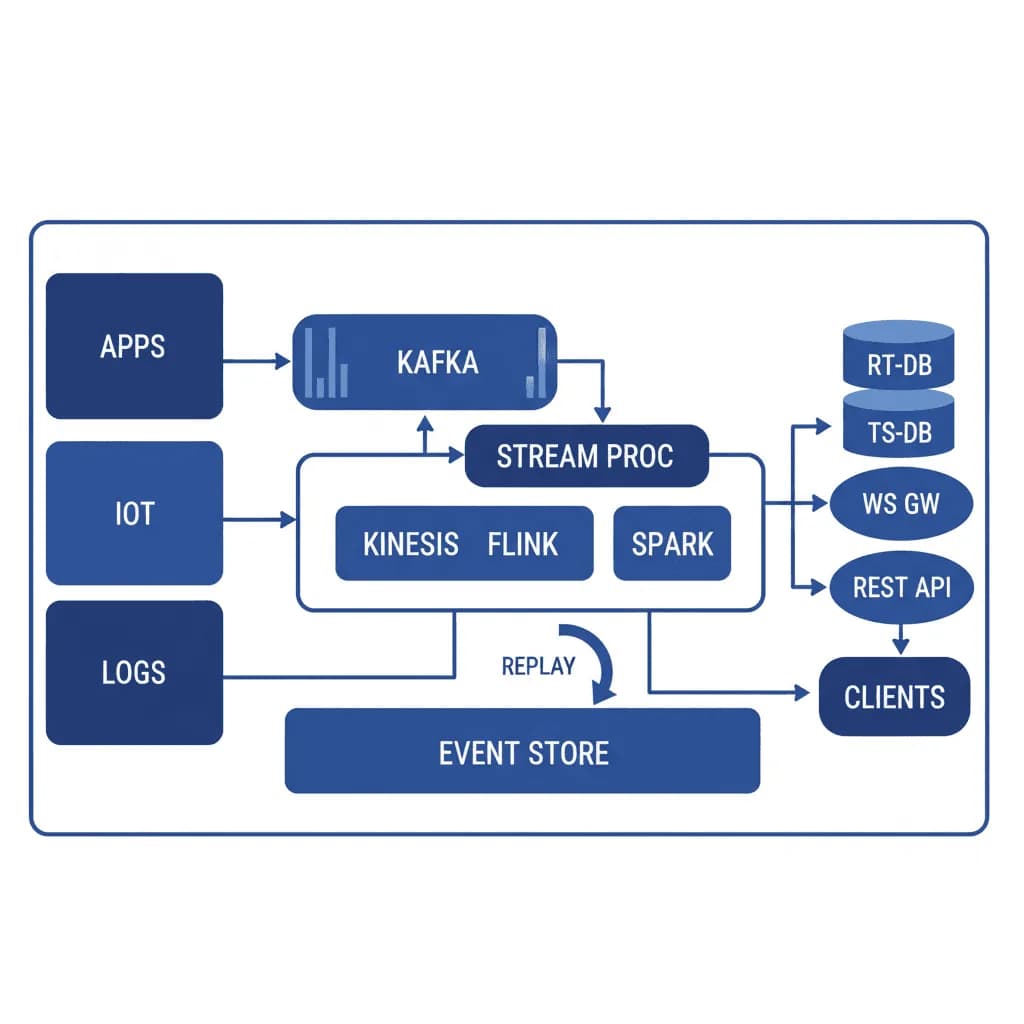
Echtzeit-Streaming-Systeme
Batch ist ein Sonderfall von Streaming. Wenn Ihr Unternehmen in Sekunden statt Stunden reagieren muss, benötigen Sie eine Architektur, die für einen kontinuierlichen Datenfluss ausgelegt ist.
|
Diskutieren Sie diese Architektur3 topics covered
Data
Category
Enterprise
Complexity
Financial Services, Logistics
Industries
3+
Technologies

Wann Sie dies benötigen
Ihre Dashboards sind veraltet, sobald jemand sie sich ansieht. Die Betrugserkennung läuft als nächtlicher Batch-Job und fängt Betrug am nächsten Morgen ab. Bestandszahlen werden stündlich aktualisiert, was zu Überverkäufen führt. Sensordaten werden gesammelt, aber erst nach der Analyse in einem nächtlichen ETL verarbeitet. Sie benötigen ein System, in dem Daten kontinuierlich von Quellen über die Verarbeitung zu Verbrauchern mit Latenzzeiten im Sub-Sekundenbereich fließen – für Echtzeit-Analysen, Live-Benachrichtigungen, Streaming-AI-Inferenz und sofortige Synchronisation zwischen Systemen.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen