Back to Architecture Patterns
AI / DataEnterprise
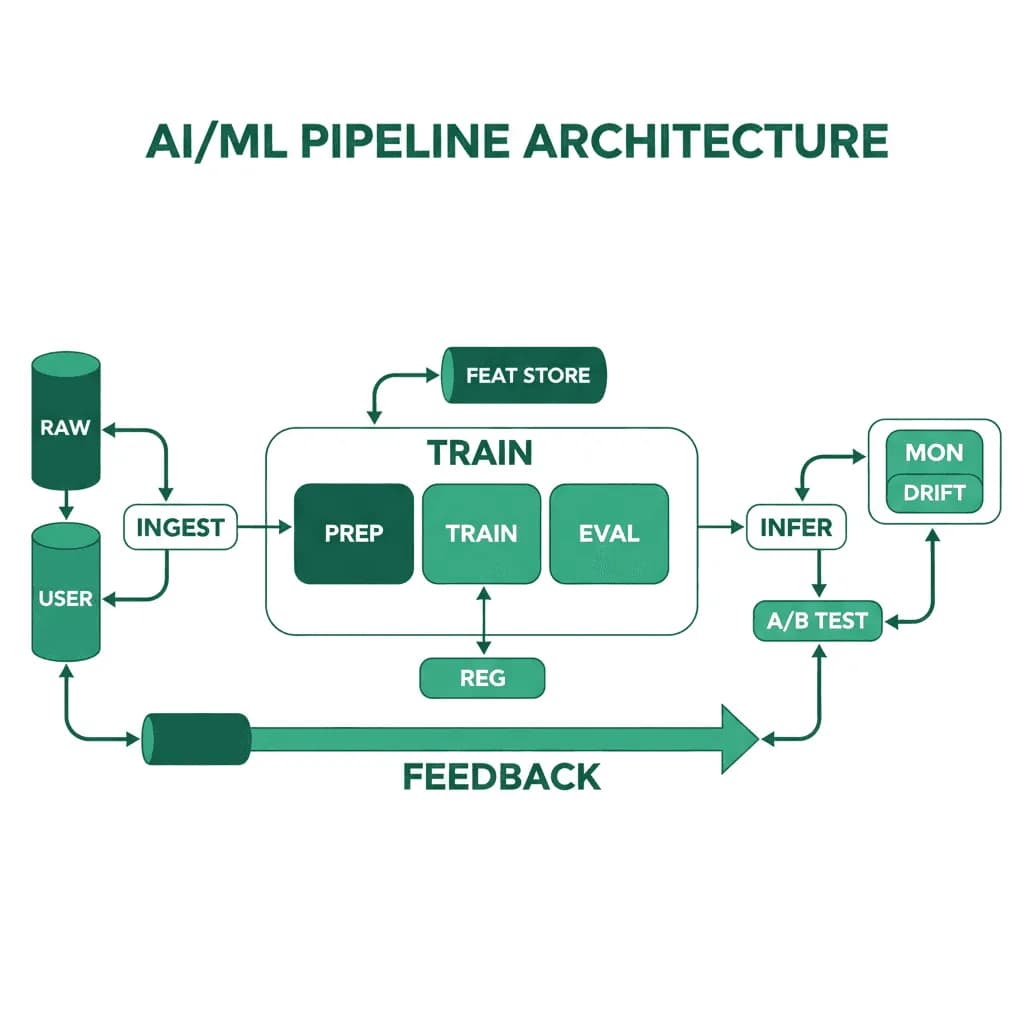
AI/ML Pipeline Architecture
Models don't run themselves. The pipeline that trains, validates, deploys, and monitors your models is the actual product — the model is just one artifact.
|
Discuss This Architecture3 topics covered
AI / Data
Category
Enterprise
Complexity
Healthcare, Financial Services
Industries
3+
Technologies

When You Need This
You've proven an ML model works in a notebook. Now you need it in production — serving predictions at scale, retraining on new data, monitoring for drift, and rolling back when a new model performs worse than the current one. The gap between a working prototype and a production ML system is enormous. You need a pipeline that handles data ingestion, feature engineering, training, validation, deployment, and monitoring as a repeatable, automated process. Without this, your "AI product" is a notebook that a data scientist reruns manually every week.

Related Architecture Patterns
Explore more design patterns and system architectures


Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch