Kembali ke Pola Arsitektur
DataEnterprise
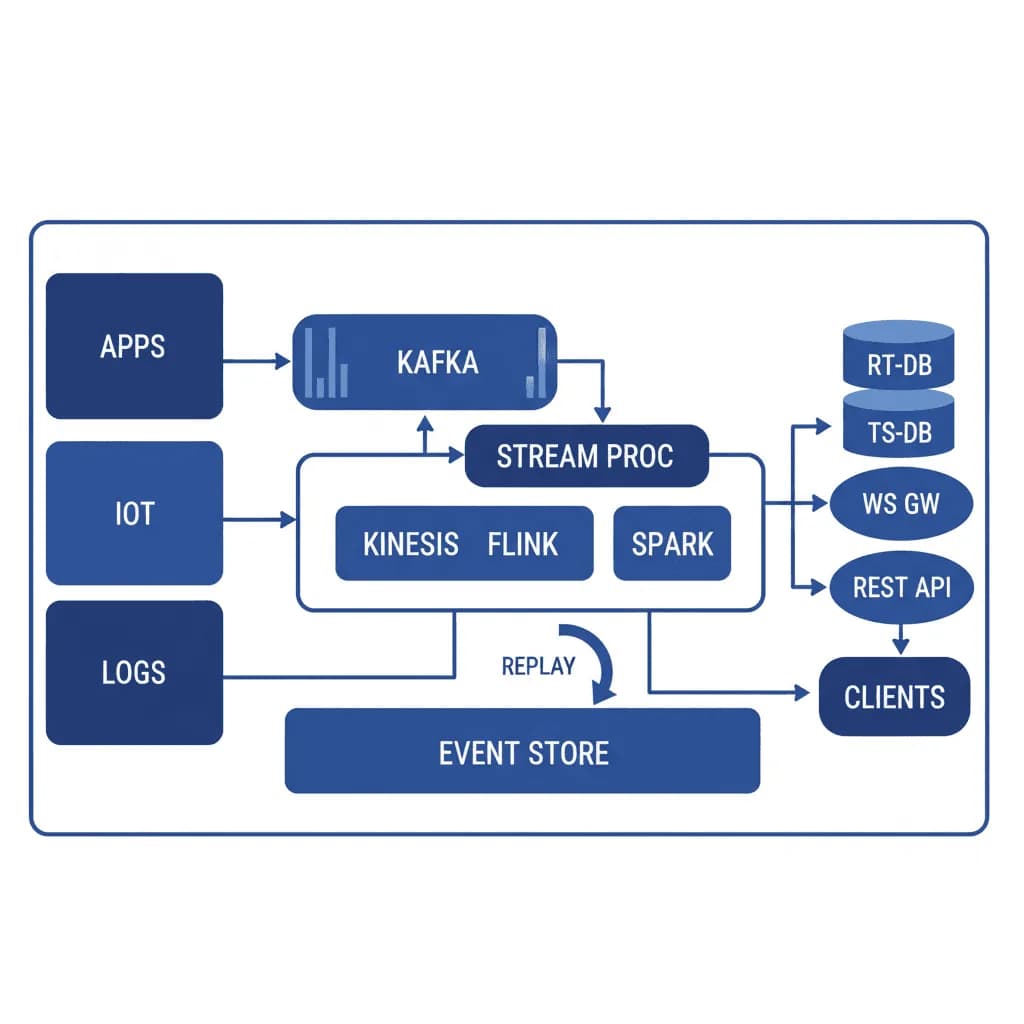
Real-Time Streaming Systems
Batch is a special case of streaming. When your business needs to react in seconds instead of hours, you need an architecture built for continuous data flow.
|
Diskusikan Arsitektur Ini3 topics covered
Data
Category
Enterprise
Complexity
Financial Services, Logistics
Industries
3+
Technologies

When You Need This
Your dashboards are stale by the time anyone looks at them. Fraud detection runs as an overnight batch job, catching fraud the next morning. Inventory counts are updated hourly, causing overselling. Sensor data is collected but not acted on until it's analyzed in a nightly ETL. You need a system where data flows continuously from sources through processing to consumers with sub-second latency — real-time analytics, live notifications, streaming AI inference, and instant synchronization between systems.

Related Architecture Patterns
Explore more design patterns and system architectures


Perlu Bantuan Menerapkan Arsitektur Ini?
Arsitek kami dapat membantu merancang dan membangun sistem menggunakan pola ini untuk kebutuhan spesifik Anda.
Hubungi Kami