Zurück zu Architekturmustern
ApplicationEnterprise
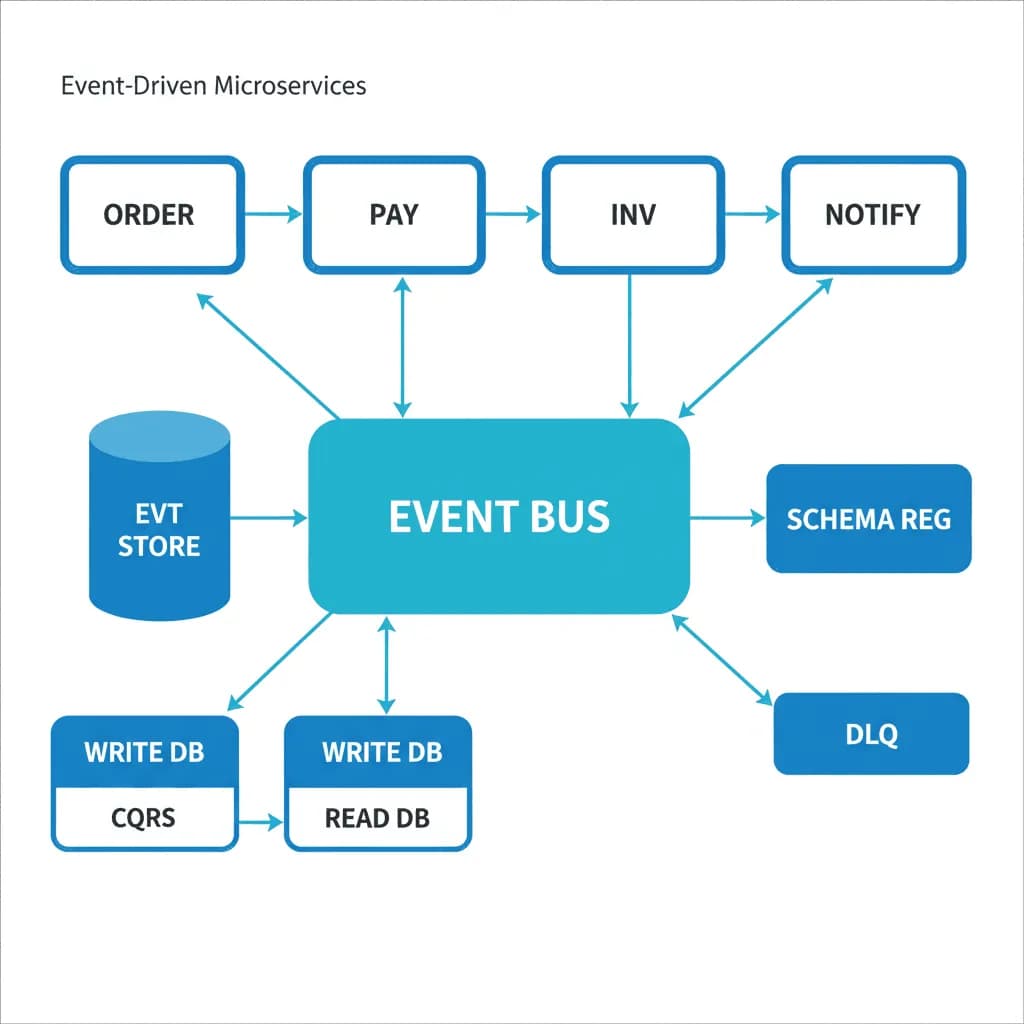
Ereignisgesteuerte Microservices
Entkoppeln Sie alles. Lassen Sie Dienste über Ereignisse kommunizieren, nicht über Erwartungen an die Verfügbarkeit des jeweils anderen.
|
Diskutieren Sie diese Architektur3 topics covered
Application
Category
Enterprise
Complexity
Finanzdienstleistungen, E-Commerce
Industries
3+
Technologies

Wann Sie dies benötigen
Ihr Monolith wird zu einem Bereitstellungsengpass — jede Änderung erfordert die Koordination zwischen Teams, und ein Fehler in der Abrechnung legt die gesamte Anwendung lahm. Oder Sie bauen ein neues System, in dem sich verschiedene Funktionen unterschiedlich schnell entwickeln: Die Auftragsverwaltung ändert sich wöchentlich, die Bestandslogik jedoch vierteljährlich. Sie benötigen Dienste, die unabhängig entwickelt, bereitgestellt und skaliert werden können und über Ereignisse kommunizieren, anstatt über synchrone API-Aufrufe, die kaskadierende Fehlerketten erzeugen.
Related Architecture Patterns
Explore more design patterns and system architectures


Benötigen Sie Hilfe bei der Implementierung dieser Architektur?
Unsere Architekten können Ihnen helfen, Systeme mit diesem Muster für Ihre spezifischen Anforderungen zu entwerfen und zu erstellen.
Kontakt aufnehmen