Retour aux Modèles d'Architecture
AI / DataEnterprise
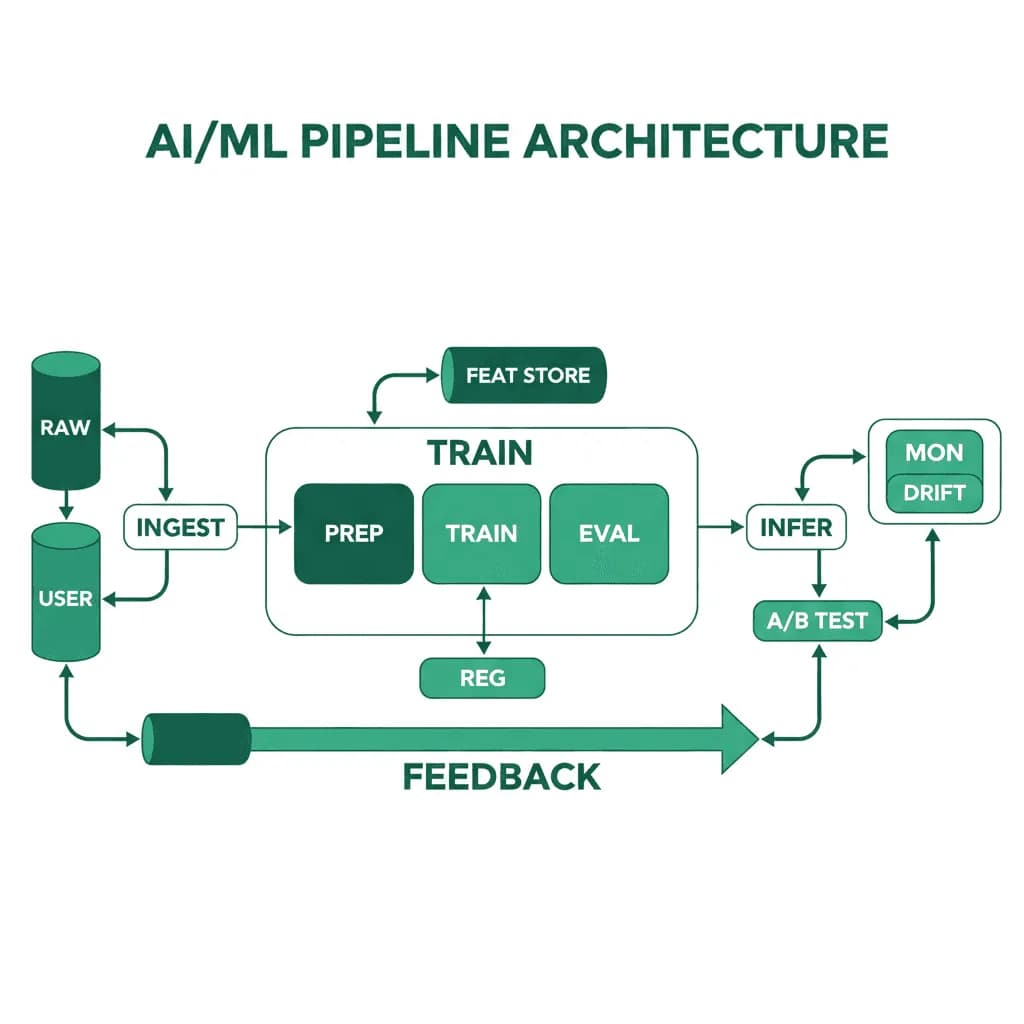
Architecture de pipeline AI/ML
Les modèles ne fonctionnent pas seuls. Le pipeline qui entraîne, valide, déploie et surveille vos modèles est le produit réel — le modèle n'est qu'un artefact.
|
Discutez de cette Architecture3 topics covered
AI / Data
Category
Enterprise
Complexity
Santé, Services Financiers
Industries
3+
Technologies

Quand Vous en Avez Besoin
Vous avez prouvé qu'un modèle ML fonctionne dans un notebook. Maintenant, vous en avez besoin en production — pour servir des prédictions à l'échelle, se réentraîner sur de nouvelles données, surveiller la dérive (drift) et revenir en arrière lorsqu'un nouveau modèle fonctionne moins bien que l'actuel. L'écart entre un prototype fonctionnel et un système ML en production est énorme. Vous avez besoin d'un pipeline qui gère l'ingestion de données, le feature engineering, l'entraînement, la validation, le déploiement et la surveillance comme un processus répétable et automatisé. Sans cela, votre "produit AI" est un notebook qu'un data scientist réexécute manuellement chaque semaine.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous