Retour aux Modèles d'Architecture
AI / DataEnterprise
Architecture de base de données vectorielle évolutive
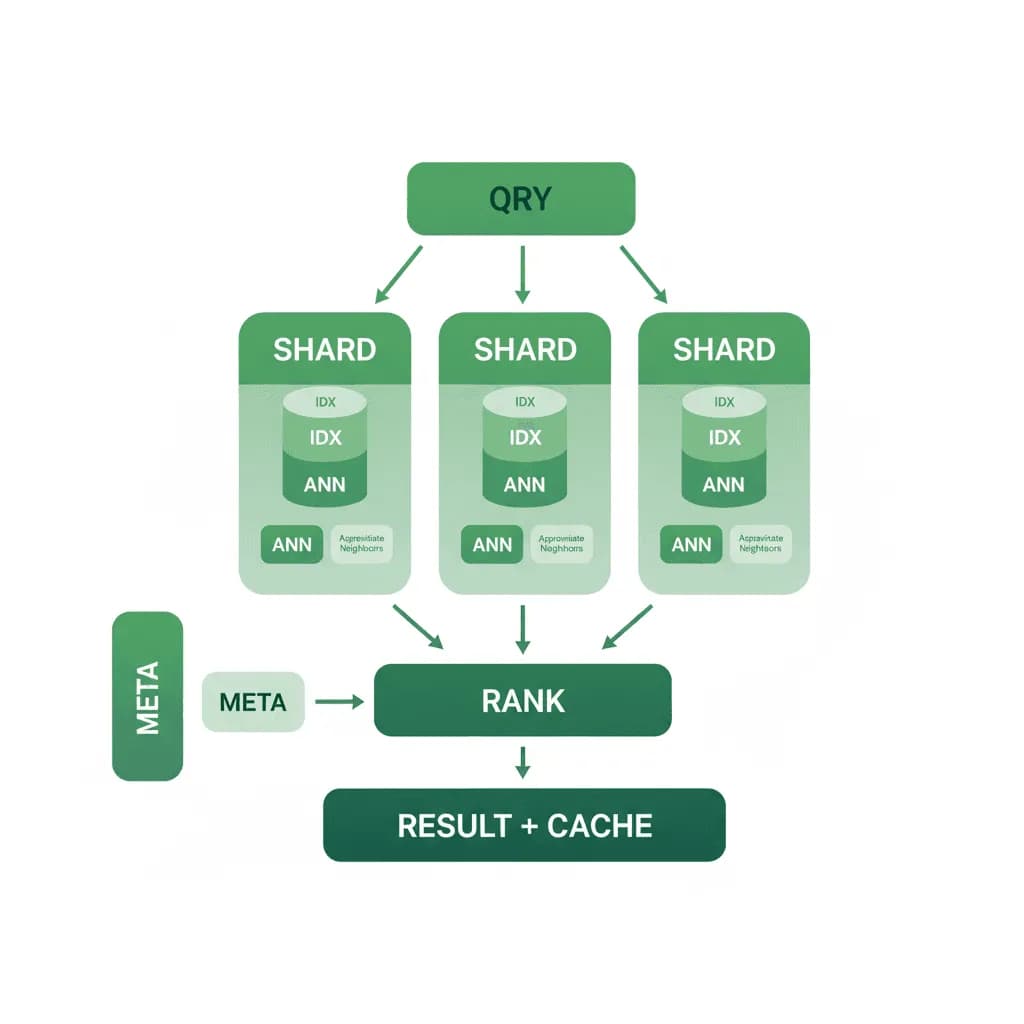
La recherche d'embeddings est facile avec 10K vecteurs. À 100M vecteurs avec un P99 inférieur à 100 ms, c'est un problème d'infrastructure — et c'est ce que ce modèle résout.
|
Discutez de cette Architecture2 topics covered
AI / Data
Category
Enterprise
Complexity
AI/ML, E-Commerce
Industries
2+
Technologies

Quand Vous En Avez Besoin
Votre pipeline RAG ou votre système de recommandation fonctionne parfaitement en développement avec quelques milliers de vecteurs. Maintenant, vous avez 50 millions d'embeddings, les requêtes nécessitent une latence inférieure à 100 ms, l'index continue de croître, et vous épuisez la mémoire. Vous avez besoin d'une architecture de base de données vectorielle qui évolue horizontalement, gère efficacement la mémoire (tout n'a pas besoin de vivre en RAM), gère les écritures concurrentes pendant l'ingestion sans dégrader les performances des requêtes, et ne coûte pas 10K $ par mois en infrastructure pour ce qui est fondamentalement un index de recherche.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous