Retour aux Modèles d'Architecture
DataEnterprise
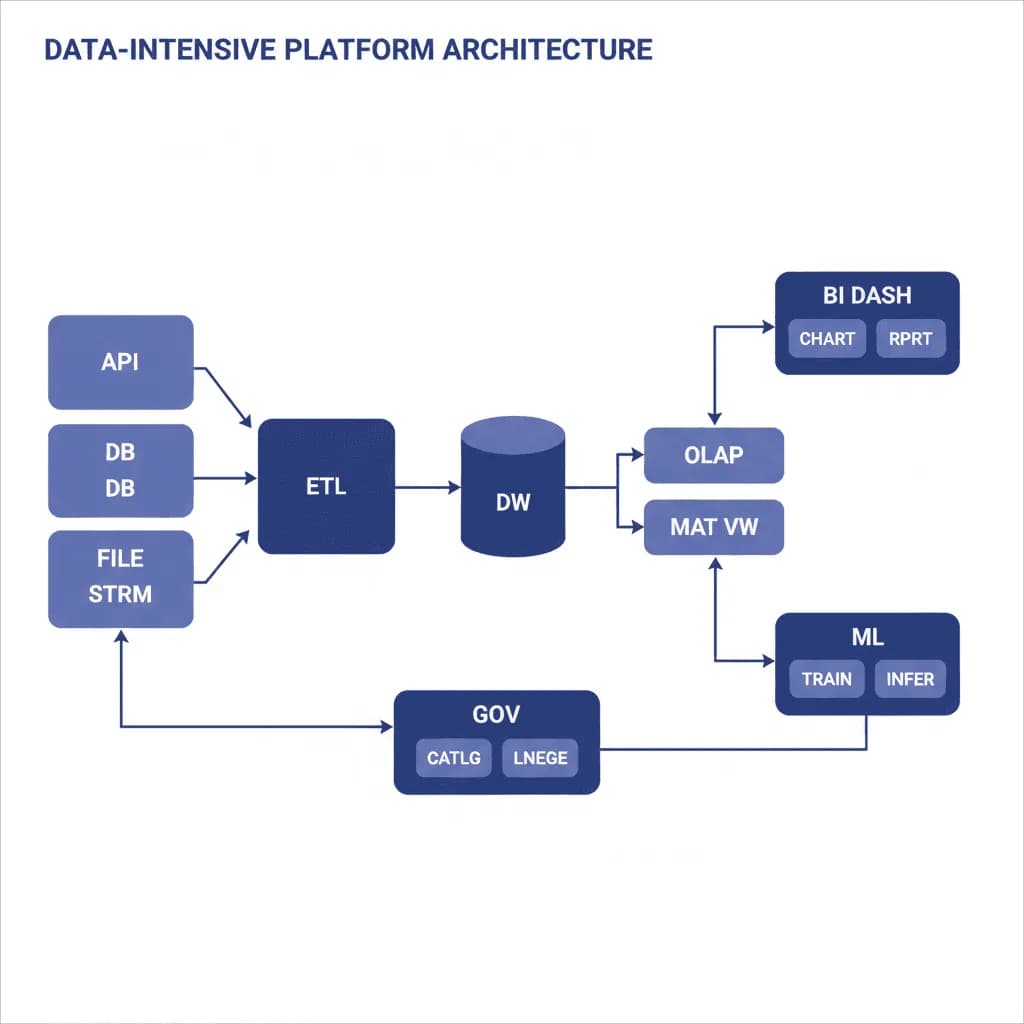
Architecture de plateforme intensive en données
Lorsque votre avantage concurrentiel réside dans vos données, la plateforme qui collecte, transforme, stocke et présente ces données est la chose la plus importante que vous construirez.
|
Discutez de cette Architecture3 topics covered
Data
Category
Enterprise
Complexity
Santé, Services Financiers
Industries
3+
Technologies

Quand cela est nécessaire
Votre organisation dispose de données dispersées sur des dizaines de systèmes — CRM, ERP, facturation, tickets de support, données de capteurs, API tierces — et personne ne peut répondre aux questions commerciales de base sans une semaine d'extraction manuelle de données. Les rapports sont construits dans des feuilles de calcul, les analystes attendent des jours que l'ingénierie des données prépare les jeux de données, et la "source unique de vérité" est la dernière base de données interrogée. Vous avez besoin d'une plateforme de données qui ingère à partir de toutes les sources, transforme les données en modèles prêts pour l'analyse, et fournit des informations aux tableaux de bord et aux systèmes AI/ML. Il ne s'agit pas d'un projet de data warehouse — c'est une plateforme qui fait des données un actif organisationnel utilisable.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous