Retour aux Modèles d'Architecture
InfrastructureAdvanced
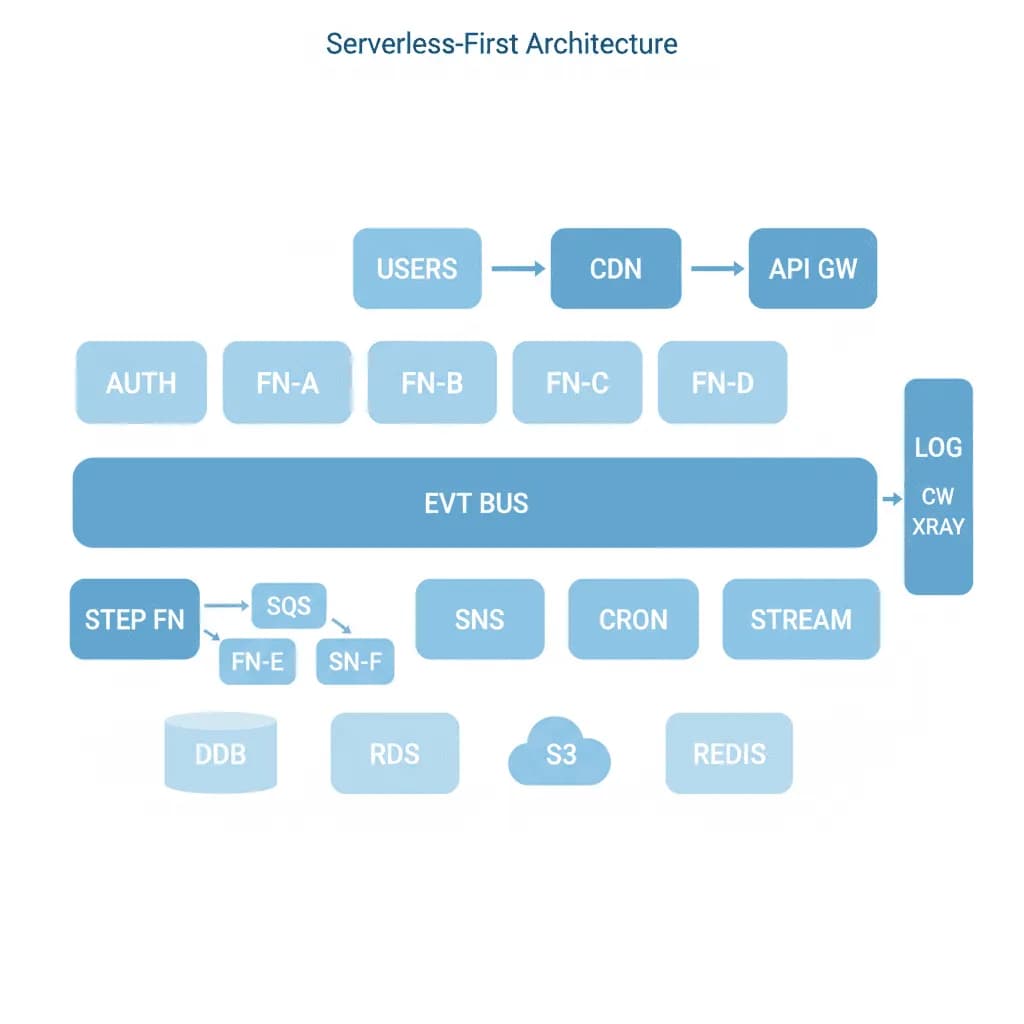
Architecture Serverless-First
Payez pour ce que vous utilisez, mettez à l'échelle jusqu'à zéro lorsque vous n'en avez pas besoin, et arrêtez complètement de gérer des serveurs — mais sachez quand l'économie cesse d'être avantageuse.
|
Discutez de cette Architecture2 topics covered
Infrastructure
Category
Advanced
Complexity
SaaS, Médias
Industries
2+
Technologies

Quand en avez-vous besoin
Votre application a un trafic variable — calme la nuit, pics pendant les heures de bureau, et des pointes imprévisibles dues à des campagnes marketing ou des événements saisonniers. Vous payez pour des serveurs qui restent inactifs 70 % du temps. Ou vous construisez un nouveau produit et ne voulez pas investir dans le provisionnement d'infrastructure, la planification de capacité et la rotation d'astreinte avant d'avoir validé l'adéquation produit-marché (product-market fit). Le serverless vous offre une tarification par requête, une mise à l'échelle automatique et une gestion d'infrastructure nulle — mais seulement lorsque les caractéristiques de la charge de travail s'y prêtent.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous