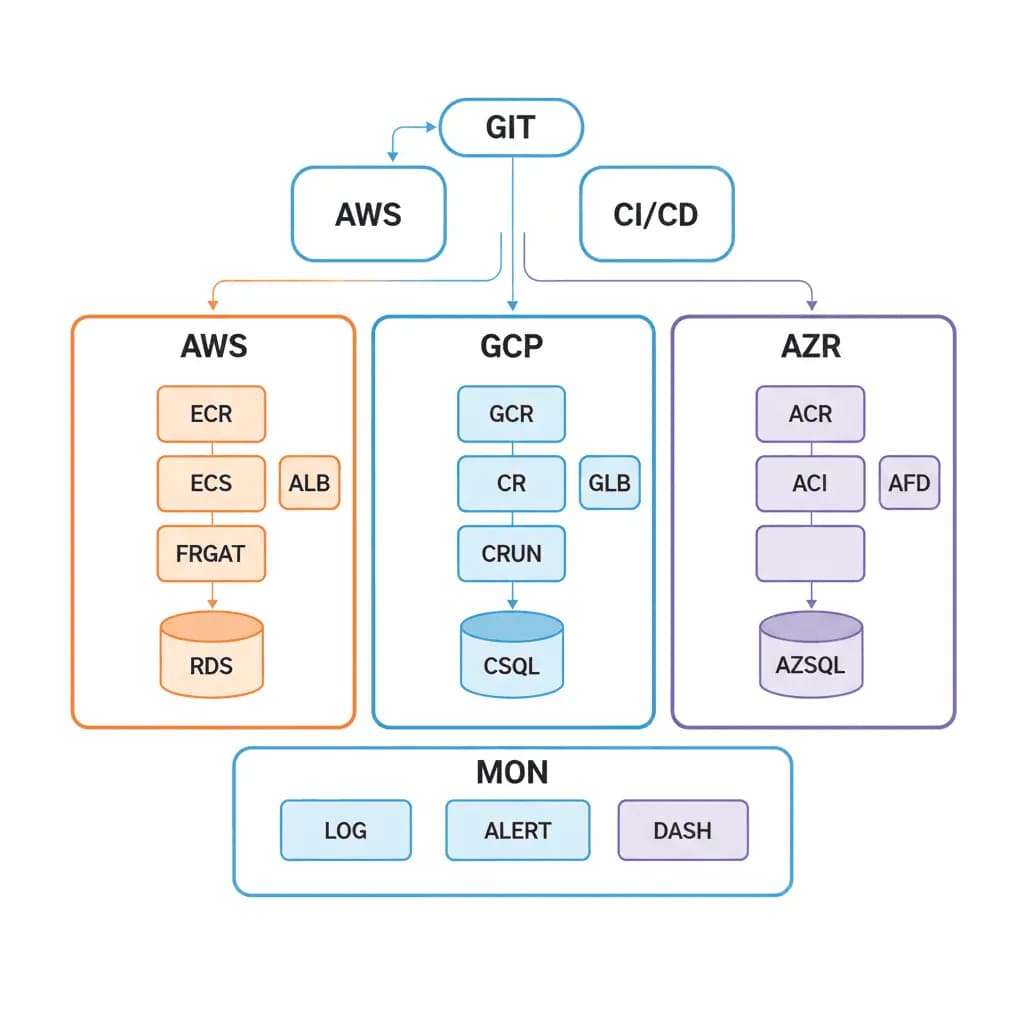
Retour aux Modèles d'Architecture
InfrastructureEnterprise
Infrastructure Cloud-Native
Une infrastructure qui est versionnée, testée et déployée comme du code applicatif — car la fiabilité de votre plateforme dépend de ce qui la sous-tend.
|
Discutez de cette Architecture2 topics covered
Infrastructure
Category
Enterprise
Complexity
Enterprise SaaS, Financial Services
Industries
2+
Technologies

Quand Vous en Avez Besoin
Votre infrastructure est gérée en cliquant à travers les consoles cloud. La dérive d'environnement entre les environnements de staging et de production provoque des problèmes de type "ça marche sur ma machine" au niveau de l'infrastructure. Le scaling nécessite une intervention manuelle, les déploiements impliquent des connexions SSH aux serveurs, et la reprise après sinistre est un Google Doc que personne n'a testé. Vous avez besoin d'une infrastructure reproductible, versionnée, auto-réparatrice et observable — une infrastructure qu'une équipe peut opérer sans connaissances héroïques.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous