Back to Architecture Patterns
AI / DataAdvanced
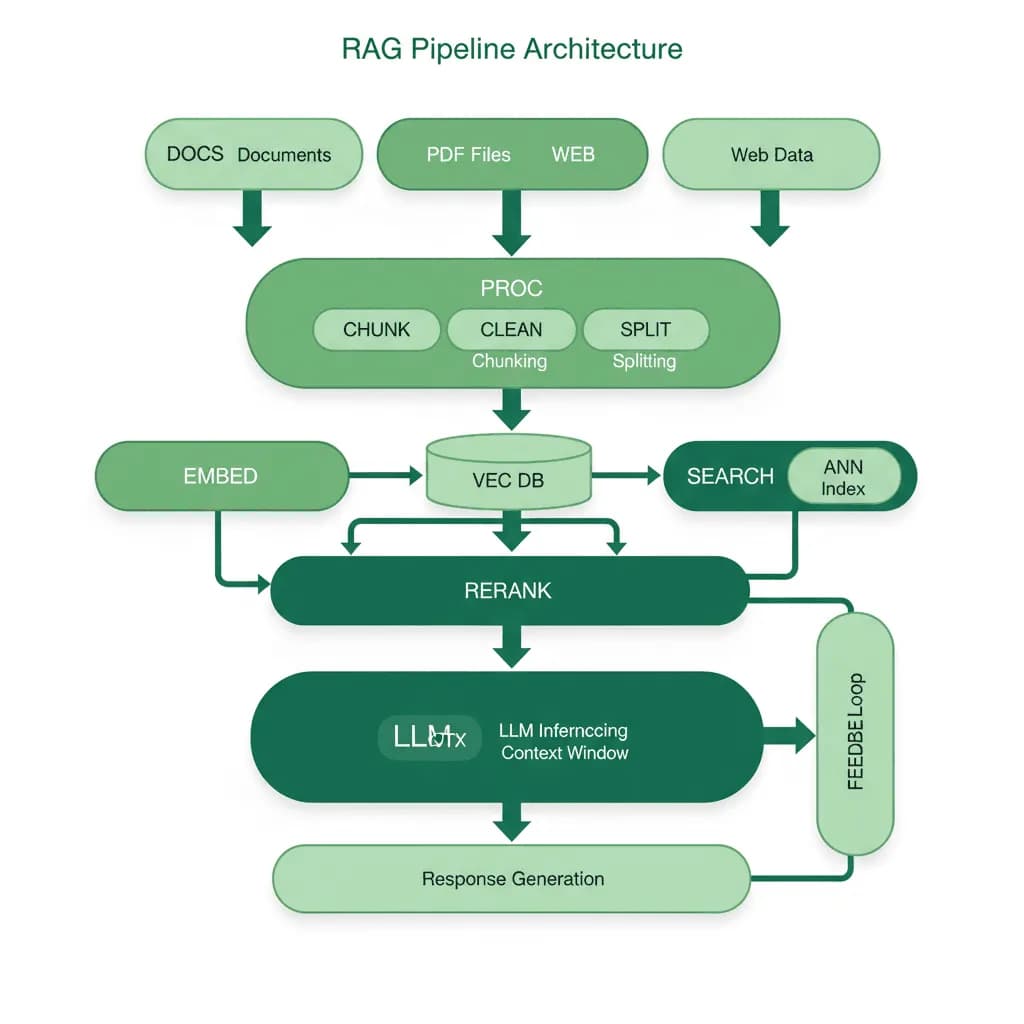
RAG Pipeline Architecture
Give your LLM access to your data without fine-tuning. RAG bridges the gap between general-purpose language models and domain-specific knowledge.
|
Discuss This Architecture2 topics covered
AI / Data
Category
Advanced
Complexity
Legal, Healthcare
Industries
2+
Technologies

When You Need This
You want to build an AI assistant that answers questions about your organization's documents — contracts, policies, knowledge bases, product documentation, medical records. Fine-tuning an LLM on your data is expensive, slow, and creates a model that's frozen at the point of training. You need an architecture where the LLM can access up-to-date, domain-specific information at query time, cite its sources, and avoid hallucinating facts that aren't in your documents. RAG (Retrieval-Augmented Generation) is how you get there.

Related Architecture Patterns
Explore more design patterns and system architectures


Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch