Back to Architecture Patterns
AI / DataEnterprise
Scalable Vector Database Architecture
Embedding search is easy at 10K vectors. At 100M vectors with sub-100ms P99, it's an infrastructure problem — and that's what this pattern solves.
|
Discuss This Architecture2 topics covered
AI / Data
Category
Enterprise
Complexity
AI/ML, E-Commerce
Industries
2+
Technologies

When You Need This
Your RAG pipeline or recommendation system works beautifully in development with a few thousand vectors. Now you have 50 million embeddings, queries need sub-100ms latency, the index keeps growing, and you're burning through memory. You need a vector database architecture that scales horizontally, manages memory efficiently (not everything needs to live in RAM), handles concurrent writes during ingestion without degrading query performance, and doesn't cost $10K/month in infrastructure for what is fundamentally a search index.

Pattern Overview
Scalable vector database architecture addresses the challenges of operating vector search at production scale: index partitioning across nodes (sharding), tiered storage (hot segments in memory, warm on SSD, cold on S3), query routing with load balancing, and autoscaling based on query load and index size. The pattern covers deployment topology, capacity planning, write/read isolation, and cost optimization. It's the infrastructure layer that makes RAG and recommendation systems viable at scale.

Reference Architecture
The architecture deploys vector database nodes in a clustered topology with separation between query nodes (read path) and data nodes (write path). An ingestion pipeline handles embedding generation and batch upserts with write buffering to avoid impacting query latency. A query router distributes searches across read replicas with shard-level parallelism. Tiered storage moves infrequently accessed segments from memory to SSD to S3, with transparent query-time loading. Autoscaling adjusts replica count based on query QPS and P99 latency.
Core Components
- Cluster Management: Milvus (our default for scale) with etcd for metadata coordination, MinIO/S3 for segment storage, and Pulsar/Kafka for write-ahead logging. Alternatively, managed services (Pinecone, Zilliz Cloud) when operational simplicity outweighs cost
- Shard & Partition Strategy: Logical partitions aligned to data boundaries (per-tenant, per-document-collection, per-time-window). Each partition is independently searchable, enabling filtered queries without scanning the full index. Shards distributed across nodes for parallel query execution
- Tiered Storage Engine: Hot tier (in-memory HNSW/IVF index) for frequently queried collections. Warm tier (memory-mapped SSD) for large collections with moderate query load. Cold tier (S3-backed) for archival collections that are searchable but tolerate higher latency. Segment-level promotion/demotion based on access patterns
- Autoscaling Controller: Horizontal pod autoscaler (HPA) on Kubernetes that scales query nodes based on QPS and P99 latency metrics. Scale-up on latency breach, scale-down on sustained low utilization. Separate scaling for ingestion workers to handle burst uploads without affecting query performance

Design Decisions & Trade-offs
Milvus vs. Pinecone vs. Qdrant vs. pgvector
pgvector is fine for < 1M vectors where you already have PostgreSQL and can tolerate ~200ms latency. Pinecone for teams that want zero operational burden and can accept the pricing (scales well but gets expensive past 10M vectors). Qdrant for a clean API with good single-node performance. Milvus for serious scale — it's the only open-source option with true distributed architecture, tiered storage, and production-grade sharding. MW defaults to Milvus for >5M vectors and Pinecone for teams that prioritize managed simplicity.
HNSW vs. IVF_FLAT vs. IVF_PQ
HNSW (Hierarchical Navigable Small World) gives the best recall at low latency but uses the most memory (full vectors in RAM). IVF_FLAT clusters vectors and searches only relevant clusters — good balance of speed and memory. IVF_PQ (Product Quantization) compresses vectors for massive memory savings but reduces recall by 3-8%. MW uses HNSW for collections under 10M vectors and switches to IVF_PQ with PQ refinement (re-score top candidates against full vectors) for larger collections where memory cost matters.
Write Isolation
Concurrent writes during ingestion degrade query latency in most vector databases. MW separates the write path: new vectors are buffered in a write-ahead log, periodically flushed into sealed segments, and merged into the searchable index during low-traffic windows. For systems requiring real-time ingestion (e.g., live document processing), we deploy separate ingestion and query node pools with different resource allocations.
Cost Optimization
Vector databases are memory-hungry. A 100M-vector collection with 1536-dimensional embeddings needs ~600GB of RAM in HNSW mode. MW optimizes cost through: (a) dimensionality reduction where feasible (Matryoshka embeddings, PCA), (b) quantization (scalar or product quantization), (c) tiered storage to push cold segments off RAM, and (d) right-sizing embedding dimensions — 768 dimensions is often sufficient when 1536 is overkill.
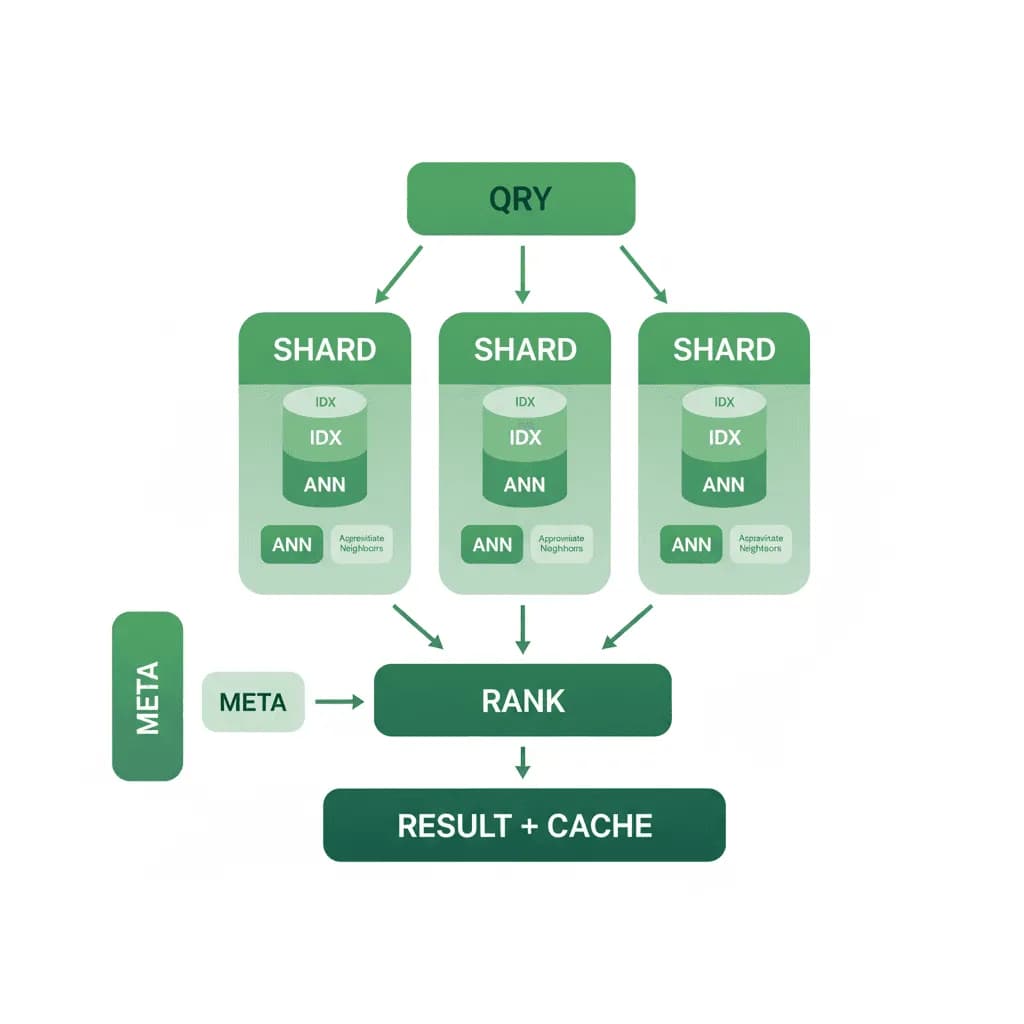
System Architecture Overview
Technology Choices
| Layer | Technologies |
|---|---|
| Vector Database | Milvus (distributed), Qdrant (single-node/small-cluster), Pinecone (managed) |
| Storage Backend | MinIO / S3 (segment storage), SSD (warm tier), RAM (hot tier) |
| Coordination | etcd (Milvus metadata), Pulsar/Kafka (write-ahead log) |
| Embedding Models | OpenAI text-embedding-3-large, Cohere embed-v4, BGE-M3, E5-large-v2 |
| Infrastructure | Kubernetes (EKS/GKE) with GPU nodes for embedding, memory-optimized nodes for query |
| Monitoring | Grafana + Milvus metrics exporter, custom P99/recall dashboards |
When to Use / When to Avoid
| Use When | Avoid When |
|---|---|
| Vector count exceeds 5M and growing, requiring horizontal scaling | You have < 1M vectors — pgvector on your existing PostgreSQL is sufficient |
| Sub-100ms P99 query latency is a hard requirement | Query latency of 500ms+ is acceptable — simpler options work |
| Multiple applications/tenants share the vector infrastructure | A single application with a single collection — use a managed service |
| Cost optimization requires tiered storage (not everything in RAM) | Budget allows fully managed services and the vendor's pricing works at your scale |
Our Approach
MW designs vector database infrastructure with a "right-size from day one, scale when measured" approach. We start with capacity planning based on vector count, dimensionality, index type, and target latency — not guesswork. Our Milvus deployments on Kubernetes include Grafana dashboards tracking segment count, memory utilization, query latency percentiles, and recall estimates. We've implemented autoscaling Milvus clusters that handle 10x traffic spikes during business hours and scale down overnight, reducing infrastructure cost by 40-60% compared to static provisioning.

Related Blueprints
- AI Customer Support Agent — Vector search powering knowledge retrieval for support responses
- AI Document Processing Pipeline — Embedding and indexing extracted document content
- AI-Driven Personalized Learning Platform — Vector similarity for content recommendations

Related Case Studies
- Milvus Autoscaling — Production Milvus cluster with Kubernetes HPA and S3-backed tiered storage
- Document Intelligence — Vector search for local document retrieval and analysis
Related Technologies
AI DevelopmentCloud Solutions
Related Architecture Patterns
Explore more design patterns and system architectures

AI / Data
RAG Pipeline Architecture
Give your LLM access to your data without fine-tuning. RAG bridges the gap between general-purpose language models and domain-specific knowledge.
AdvancedView

AI / Data
AI/ML Pipeline Architecture
Models don't run themselves. The pipeline that trains, validates, deploys, and monitors your models is the actual product — the model is just one artifact.
EnterpriseView

Data
Data-Intensive Platform Architecture
When your competitive advantage is in your data, the platform that collects, transforms, stores, and surfaces that data is the most important thing you'll build.
EnterpriseView
Frequently Asked Questions
MicrocosmWorks generally recommends pgvector for projects with fewer than 5-10 million vectors where the team already uses PostgreSQL, as it avoids introducing a new infrastructure component and supports hybrid SQL-plus-vector queries natively. Beyond 10 million vectors or when you need sub-50ms p99 latency at high concurrency, a purpose-built vector database like Qdrant, Weaviate, or Milvus provides significantly better performance through optimized indexing algorithms and GPU-accelerated search. We help clients make this decision during architecture review by benchmarking their actual query patterns and growth projections.
MicrocosmWorks designs vector database clusters with hash-based or metadata-based sharding strategies that distribute vectors across nodes while keeping semantically related data co-located for efficient search. We implement query routing layers that fan out search requests to relevant shards and merge results using a global top-K aggregation, maintaining sub-100ms latency even across dozens of shards. Our monitoring dashboards track shard balance, query distribution, and replication lag to prevent hotspots as your dataset scales.
MicrocosmWorks applies scalar quantization (reducing float32 to int8) and product quantization to compress vector storage by 4-8x with typically less than 2% degradation in recall, which we validate through A/B testing on your actual query workload before deploying to production. We also implement a two-stage retrieval approach where quantized vectors serve the initial candidate retrieval and full-precision vectors are used only for final re-ranking of the top results. This hybrid strategy lets clients store hundreds of millions of vectors at a fraction of the cost while maintaining search quality indistinguishable from uncompressed operation.
MicrocosmWorks deploys vector databases in multi-replica configurations with synchronous replication for write durability and read replicas distributed across availability zones for fault tolerance and load balancing. We configure automated failover with health-check-driven leader election so that a node failure results in less than 10 seconds of read unavailability and zero data loss. Our infrastructure-as-code templates include pre-configured backup schedules, point-in-time recovery, and disaster recovery runbooks tailored to each vector database engine.
MicrocosmWorks architects multi-collection vector database deployments where each application or embedding model gets its own isolated collection with appropriate index configurations, while sharing the underlying cluster infrastructure for cost efficiency. We implement a unified query gateway that routes requests to the correct collection based on application context and applies collection-specific pre-processing like query embedding with the matching model. This multi-tenant vector database approach typically reduces infrastructure costs by 40-60% compared to running separate clusters per application.
Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch