Mimari Desenlere Geri Dön
AI / DataEnterprise
Scalable Vector Database Architecture
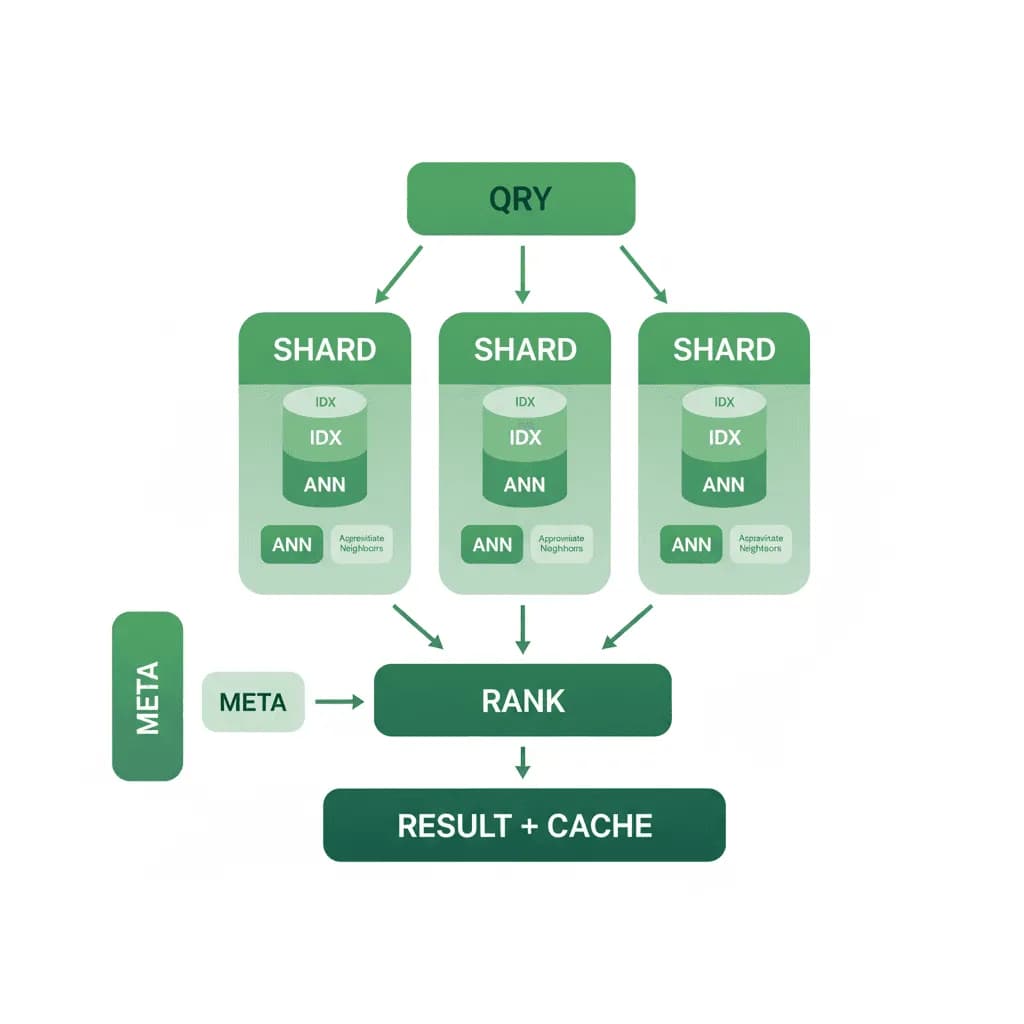
Embedding search is easy at 10K vectors. At 100M vectors with sub-100ms P99, it's an infrastructure problem — and that's what this pattern solves.
|
Bu Mimariyi Tartışın2 topics covered
AI / Data
Category
Enterprise
Complexity
AI/ML, E-Commerce
Industries
2+
Technologies

When You Need This
Your RAG pipeline or recommendation system works beautifully in development with a few thousand vectors. Now you have 50 million embeddings, queries need sub-100ms latency, the index keeps growing, and you're burning through memory. You need a vector database architecture that scales horizontally, manages memory efficiently (not everything needs to live in RAM), handles concurrent writes during ingestion without degrading query performance, and doesn't cost $10K/month in infrastructure for what is fundamentally a search index.

Related Architecture Patterns
Explore more design patterns and system architectures


Bu Mimarinin Uygulanmasında Yardıma İhtiyacınız Var mı?
Mimarlarımız, bu deseni kullanarak belirli gereksinimleriniz için sistemler tasarlamanıza ve oluşturmanıza yardımcı olabilir.
İletişime Geçin