Retour aux Modèles d'Architecture
ApplicationEnterprise
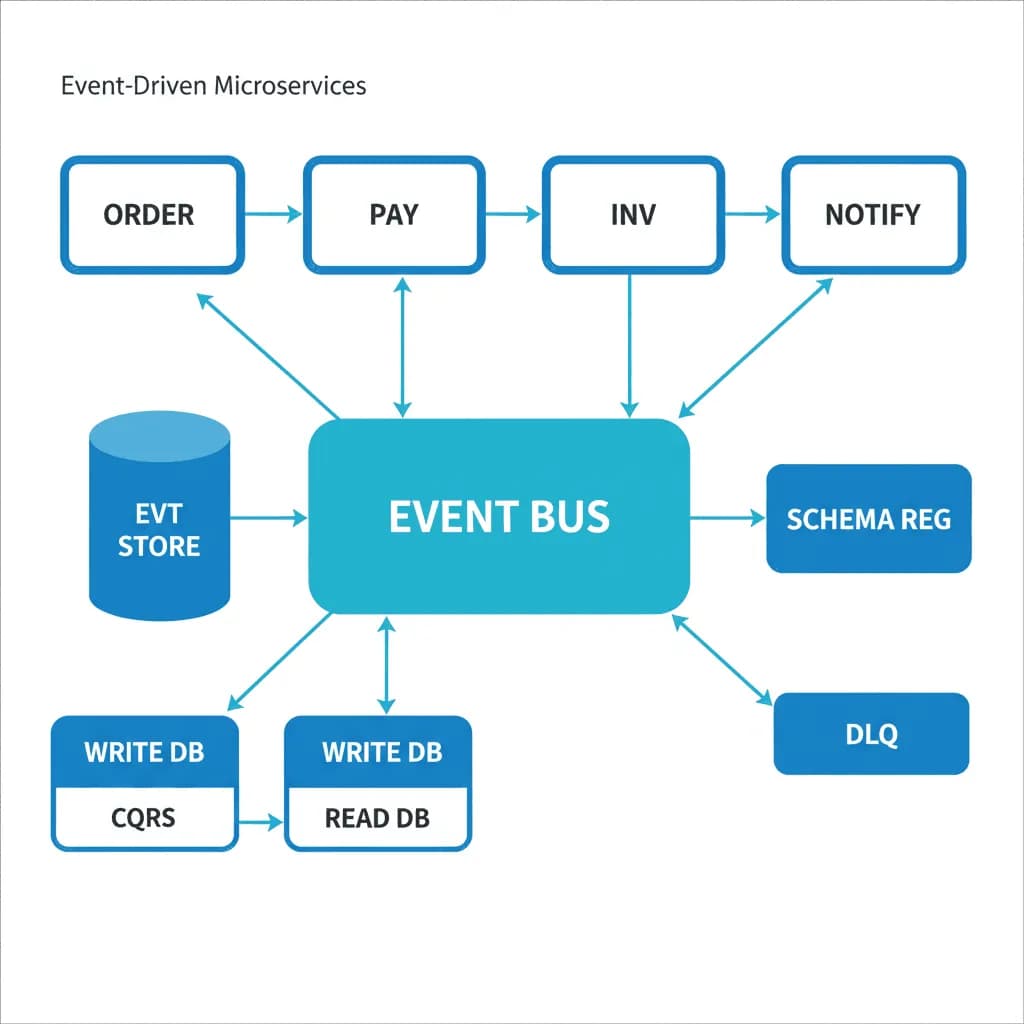
Microservices pilotés par les événements
Découplez tout. Laissez les services communiquer via des événements, et non des attentes concernant la disponibilité de chacun.
|
Discutez de cette Architecture3 topics covered
Application
Category
Enterprise
Complexity
Services Financiers, E-Commerce
Industries
3+
Technologies

Quand vous en avez besoin
Votre monolithe devient un goulot d'étranglement de déploiement — chaque changement nécessite une coordination entre les équipes, et un bug dans la facturation fait tomber toute l'application. Ou vous construisez un nouveau système où différentes capacités évoluent à des rythmes différents : la gestion des commandes change toutes les semaines, mais la logique d'inventaire change tous les trimestres. Vous avez besoin de services qui peuvent être développés, déployés et mis à l'échelle indépendamment, communiquant via des événements plutôt que des appels d'API synchrones qui créent des chaînes de défaillances en cascade.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous