아키텍처 패턴으로 돌아가기
InfrastructureAdvanced
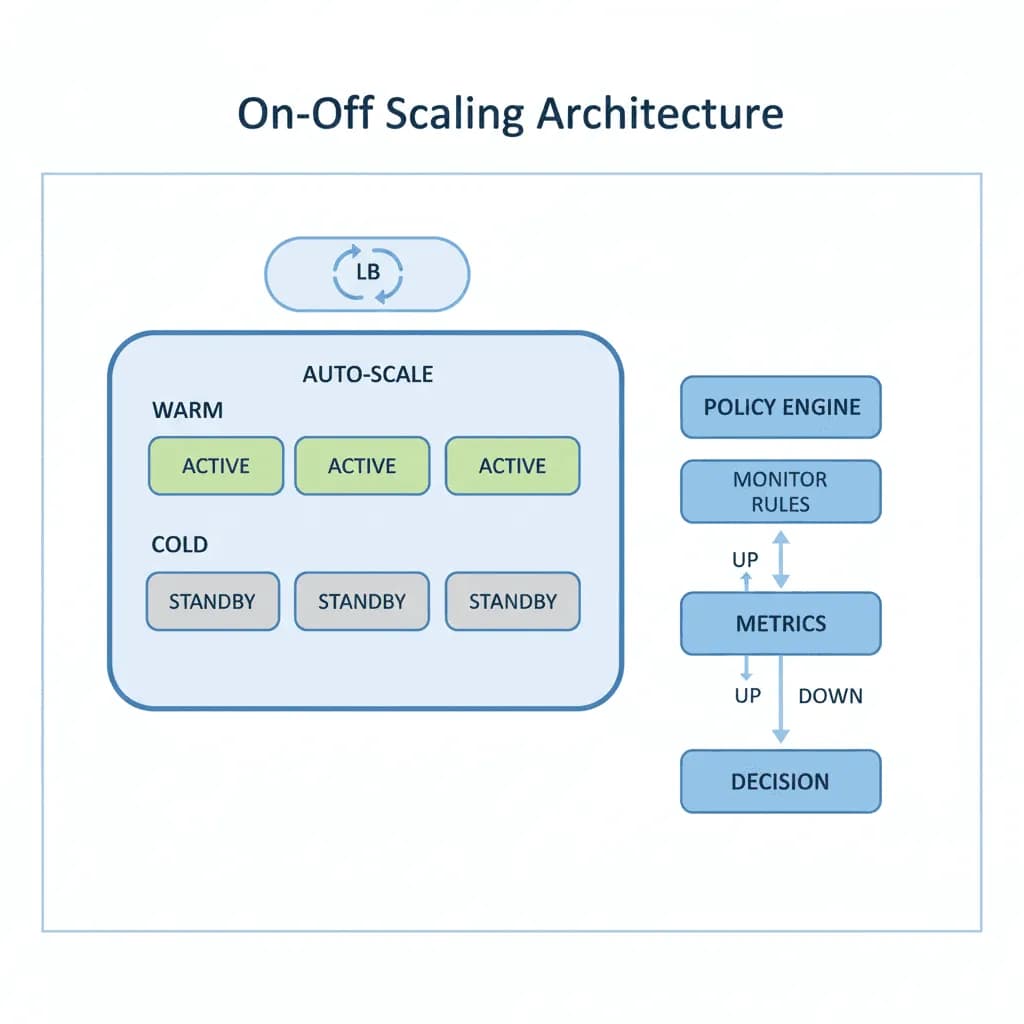
On-Off Scaling Architecture
Don't pay for idle GPUs. Provision compute just-in-time, process the workload, and tear it down — turning capital expense into a per-job operating cost.
|
이 아키텍처에 대해 논의하세요2 topics covered
Infrastructure
Category
Advanced
Complexity
AI/ML, Media & Entertainment
Industries
2+
Technologies

When You Need This
Your workload is bursty — video encoding jobs that spike when content is uploaded, ML training runs that need 8 GPUs for 4 hours then nothing, batch inference jobs triggered by business events, or rendering pipelines that run overnight. You're either over-provisioned (paying for idle resources 80% of the time) or under-provisioned (jobs queue for hours during peaks). You need an architecture that provisions exactly the compute you need, when you need it, and releases it when the job completes — without the cold-start penalty that makes "scale to zero" impractical for GPU workloads.

Related Architecture Patterns
Explore more design patterns and system architectures


자주 묻는 질문
배치 중심 또는 주기적 워크로드를 가진 MicrocosmWorks 클라이언트는 온오프 스케일링을 구현한 후 일반적으로 60-80%의 클라우드 비용 절감을 경험합니다. 이는 컴퓨팅 리소스가 연중무휴 24시간 실행되는 대신 활성 처리 시간 동안에만 실행되기 때문입니다. 예를 들어, 매일 4시간 동안 실행되는 데이터 처리 파이프라인은 24시간 전체가 아닌 해당 4시간에 대해서만 비용을 지불하도록 실제 사용량 텔레메트리를 기반으로 스케일링 정책을 설계합니다. 당사의 아키텍트는 구현 시작 전에 탐색 단계에서 고객의 워크로드 패턴을 분석하여 정확한 절감액을 예측합니다.
콜드 스타트 시간은 사전 워밍된 노드 풀의 컨테이너화된 애플리케이션의 경우 2-3초, 특수 GPU 인스턴스 또는 대규모 모델 로딩이 필요한 워크로드의 경우 5-10분까지 다양하며, MicrocosmWorks는 이러한 지연을 최소화하기 위해 여러 기술을 사용합니다. 우리는 과거 트래픽 패턴 및 예약된 이벤트를 사용하여 예상 수요가 발생하기 전에 리소스를 가동하는 예측 스케일링을 구현하고, 지연 시간에 민감한 워크로드에는 컨테이너 이미지 사전 풀링 및 웜 풀 예약을 사용합니다. 콜드 스타트를 전혀 허용할 수 없는 애플리케이션의 경우, 수요가 발생하면 공격적으로 스케일업하는 최소한의 웜 베이스라인을 유지합니다.
MicrocosmWorks는 큐 깊이, CPU utilization 또는 맞춤형 애플리케이션 지표에 의해 트리거되는 공격적인 스케일업 정책과, 스래싱을 방지하기 위한 쿨다운 기간을 포함하는 보다 점진적인 스케일다운 정책을 결합한 반응형 자동 스케일링을 구현합니다. 우리는 시스템이 한 번에 하나의 인스턴스씩 수요를 쫓는 대신 지속적인 성장을 예측하도록 스케일업 이벤트 동안 초과 프로비저닝 버퍼를 구성합니다. 플래시 세일 또는 바이럴 이벤트와 같이 진정으로 예측 불가능한 급증의 경우, 마케팅 또는 운영 캘린더의 이벤트 기반 트리거를 사용하여 용량을 사전 프로비저닝합니다.
MicrocosmWorks는 유휴 기간 동안 스토리지의 영구성과 즉각적인 가용성을 유지하면서 컴퓨팅을 0으로 스케일링하는 Aurora Serverless, Neon 또는 PlanetScale과 같은 서버리스 데이터베이스 오퍼링을 사용하여 데이터베이스에 온오프 스케일링을 적용합니다. 서버리스 데이터베이스를 사용할 수 없는 상태 저장 워크로드의 경우, 최소한의 기본 인스턴스를 항상 실행 상태로 유지하면서 쿼리 로드에 따라 복제본을 추가하고 제거하는 읽기 복제본 스케일링을 구현합니다. 이 하이브리드 접근 방식은 클라이언트가 종료 및 재시작 주기 동안 데이터베이스 상태를 관리하는 복잡성 없이 데이터 티어 스케일링의 비용 이점을 누릴 수 있도록 합니다.
MicrocosmWorks는 Grafana 또는 Datadog 대시보드를 사용하여 인스턴스 수, 스케일링 이벤트 지연 시간, 실패한 스케일링 시도, 그리고 원하는 용량과 실제 용량 간의 격차를 실시간으로 추적하는 포괄적인 스케일링 관찰 가능성(observability)을 배포합니다. 우리는 스케일링 실패, 스케일링 상한이 너무 낮음을 시사하는 지속적인 높은 사용률, 그리고 폭주 스케일링을 나타내는 비용 이상에 대해 다중 채널 경고를 구성합니다. 우리의 런북에는 클라우드 공급자 인스턴스 제한 도달 또는 특정 가용 영역에서 용량 부족 오류 발생과 같은 일반적인 실패 모드에 대한 자동화된 문제 해결 방법이 포함되어 있습니다.