Retour aux Modèles d'Architecture
InfrastructureAdvanced
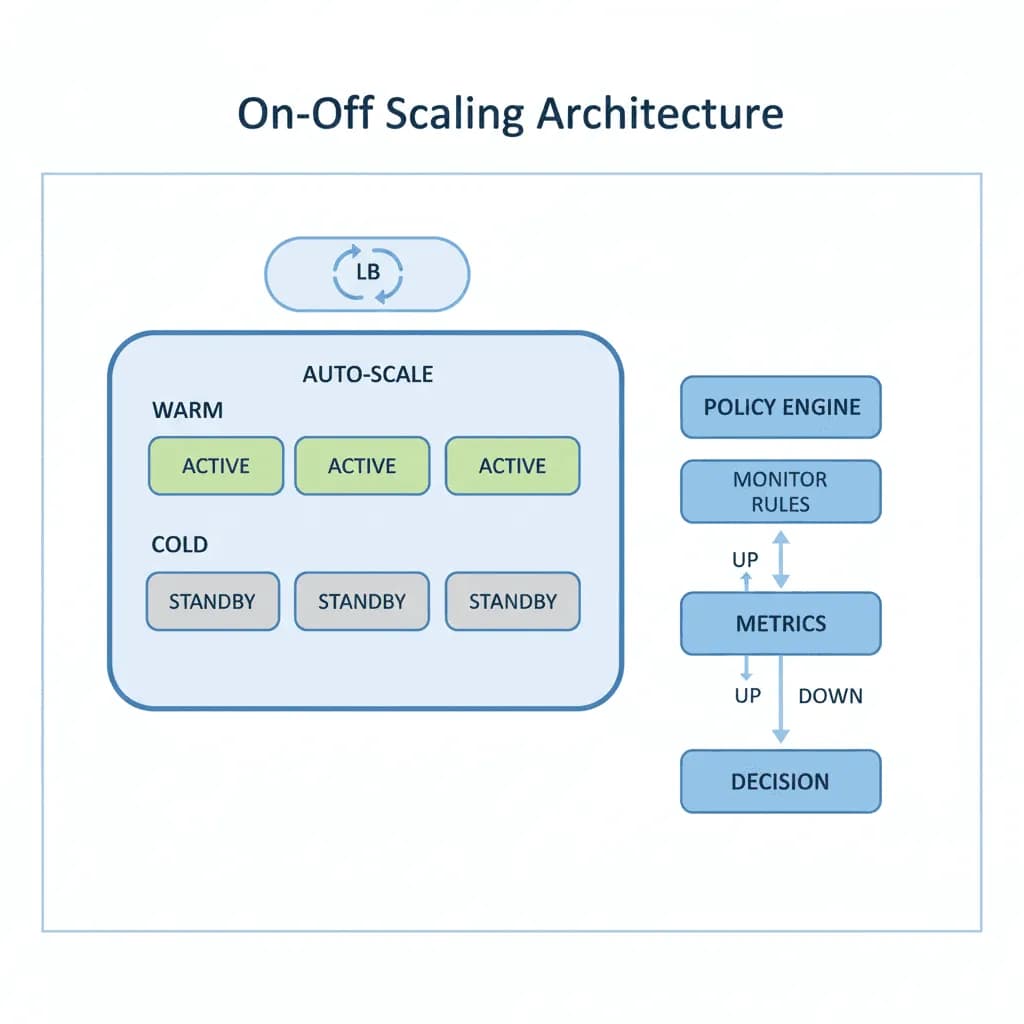
Architecture de Scaling On-Off
Ne payez pas pour les GPU inactifs. Provisionnez la puissance de calcul juste à temps, traitez la charge de travail et déprovisionnez-la — transformant les dépenses en capital en un coût d'exploitation par tâche.
|
Discutez de cette Architecture2 topics covered
Infrastructure
Category
Advanced
Complexity
AI/ML, Media & Entertainment
Industries
2+
Technologies

Quand vous en avez besoin
Votre charge de travail est intermittente — des tâches d'encodage vidéo qui augmentent brusquement lorsque du contenu est téléchargé, des exécutions d'entraînement ML qui nécessitent 8 GPU pendant 4 heures puis rien, des tâches d'inférence par lots déclenchées par des événements commerciaux, ou des pipelines de rendu qui s'exécutent pendant la nuit. Vous êtes soit sur-provisionné (payant pour des ressources inactives 80 % du temps), soit sous-provisionné (les tâches s'accumulent pendant des heures lors des pics). Vous avez besoin d'une architecture qui provisionne exactement la puissance de calcul dont vous avez besoin, quand vous en avez besoin, et la libère une fois la tâche terminée — sans la pénalité de "cold-start" qui rend le "scale to zero" impraticable pour les charges de travail GPU.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous