Retour aux Modèles d'Architecture
DataEnterprise
Systèmes de Streaming en Temps Réel
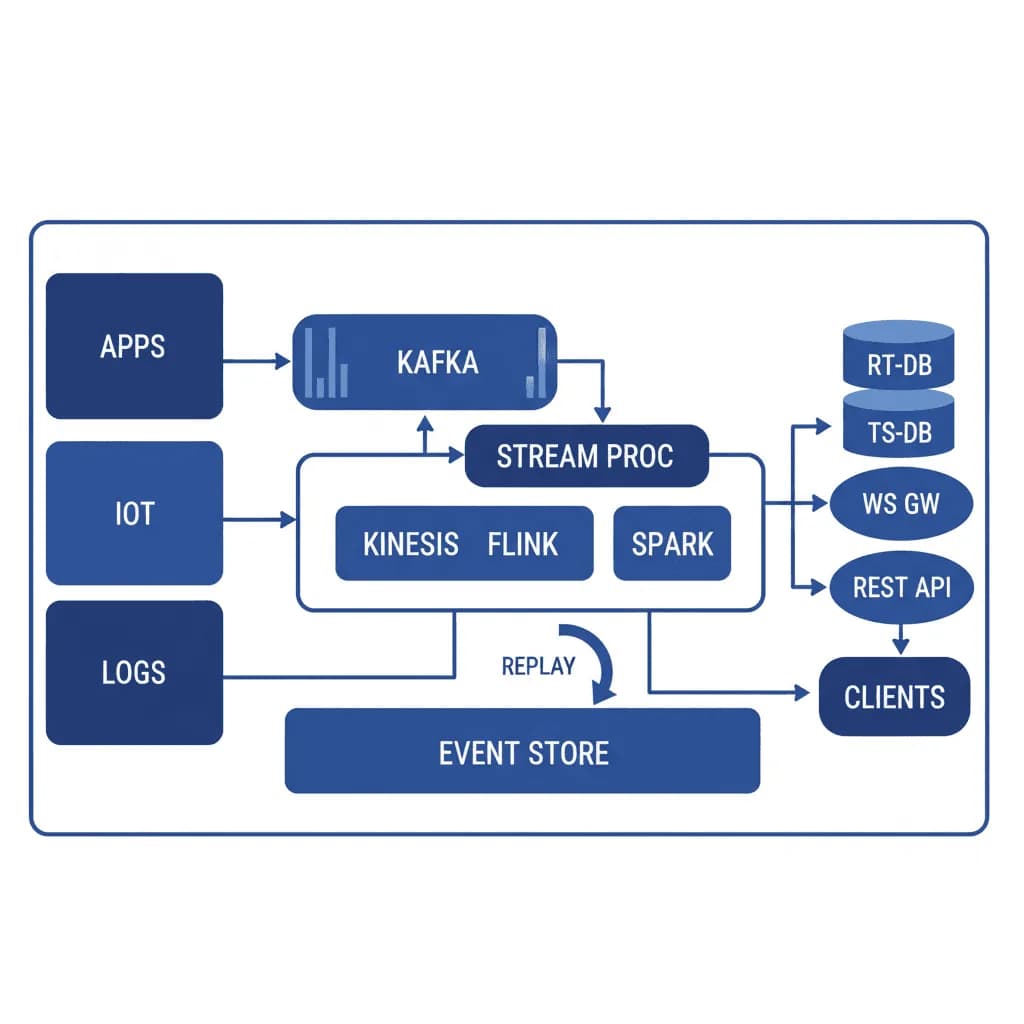
Le traitement par lots est un cas particulier du streaming. Lorsque votre entreprise a besoin de réagir en quelques secondes au lieu de quelques heures, il vous faut une architecture conçue pour un flux de données continu.
|
Discutez de cette Architecture3 topics covered
Data
Category
Enterprise
Complexity
Financial Services, Logistics
Industries
3+
Technologies

Quand en avez-vous besoin
Vos tableaux de bord sont obsolètes au moment où quelqu'un les consulte. La détection de fraude est exécutée sous forme de tâche par lots nocturne, identifiant la fraude le lendemain matin. Les décomptes d'inventaire sont mis à jour toutes les heures, entraînant des surventes. Les données de capteurs sont collectées mais ne sont pas utilisées avant d'être analysées dans un ETL nocturne. Vous avez besoin d'un système où les données circulent en continu des sources, via le traitement, vers les consommateurs avec une latence inférieure à la seconde — `real-time analytics`, notifications en direct, inférence `AI` en `streaming`, et synchronisation instantanée entre les systèmes.
Related Architecture Patterns
Explore more design patterns and system architectures


Avez-vous besoin d'aide pour implémenter cette architecture ?
Nos architectes peuvent vous aider à concevoir et construire des systèmes utilisant ce modèle pour vos besoins spécifiques.
Contactez-nous